原创精品,请慢慢品尝,手机阅读体验也不错!大屏电脑放大到125%阅读效果更佳!
写在前面
曾任某直播公司,海外直播部,主导了核心大数据开发,架构出颇具特色的大数据及数据湖平台,数据量超500亿。技术上主要整合三架马车:离线计算(Hive),实时计算(Flink)与自建调度平台(Java)。在该平台的基础上推出:1、PUSH推送提数系统,造了数亿PUSH推送数据,给拉新做日活作出了贡献,相当创造了一名不用发工资的虚拟高级技术开发。2、活动数据系统(离线),创造了面向界面操作就能生成HSQL的大胆尝试,Idea,个人认为是公司首创,机器写Hive大数据任务效率提升1000倍(半年机器编写数万Hive任务),由此带来数千自动化常规活动,躺着给公司充KPI。3、活动数据系统(实时),打造出实时小活动与小任务系统,功能历史性强大,快速灵活上线,深受运营同学的喜欢,再次躺着充KPI。4、主播计薪系统,一搞就是四年,我们处于最下游的数据大集成阶段,多时区多国家多分类超复杂计薪需求开发,合作方综横交错,出事风险概率是2000%,但四年零事故(归属),零事故,确实是零事故,又创造了历史,团队风采再现,日出东方利中国,这里体现的不仅是专业,还有敬业、爱业与守业。5、营收大活动系统,通过不断开发小组件,积木式搭建庞大复杂的大营收活动体系,以极少的人力完成疯狂的需求开发计划,PlanA, PlanB, PlanC一路进化,到达项目组最伟大的营收S级目标,又一次伟大的项目尝试,二名核心开发分别获得年度优秀员工,体现了众望所归的实力。6、搜索系统。7、数据浏览系统等。积累了一定的经验与技巧,是一次真实而又触手可及的大数据及数据湖实战经验分享(不是虚玩概念),希望对大家有所收获。
温馨提示:本文章对数据进行了脱敏或假设处理,对公司计算平台也引用公开的资料,不涉及公司的具体业务与隐私。
历史背景
海外部门成立半年后,随着业务的不断推进,业务运营部门,特别海外各国运营团队,对数据的需求非常急切,基本是当天上线功能,第二天就希望拿到数据,当时最核心矛盾如下:
1、各国运营团队想尽办法得到各种统计数据,统计口径五花百门,没有现成数据可参考,而且总要求以最快速度给到;
2、公司级数据中心仅能提供核心统计数据,如日活,观看时长或充值等指标,无法提供其它个性化数据,或2-8周的开发周期;
3、我们团队有一定的数据开发能力,能以最快的速度提供数据(1-3天),但我们做数据不符合公司战略方向。
经过长时间的讨论与合作,最后达成如下结论:1、公司对外口径核心统计数据以数据中心为准(如财务计薪); 2、大量业务统计或开发数据需求以我们为准。从此开启了我们小组的数据研究、探索与开发之旅。但业务数据有如下特色:散、乱、复杂、烦、紧迫性、容易扯皮,都说是烫手的山芋,而且我们开发人力也不足,所以要我们在技术上有创新,以适应这个高强度的要求(公司企业文化也提倡:勇于承担更多模糊不清的边界工作,我们团队算是充分落实了口号,我们也自称是打游击的小八路,就等着我们成长吧)。
思想准备
刚合并到海外团队时,海外项目是公司级战略重点项目,正所谓政通人和,百废俱兴,重整团队搞大建设,场景一片生机勃勃。但我们刚来此地,人生地不熟,怕有人打退堂鼓,所以统一了思想:不埋怨不挑活,来什么做什么,并做好什么,再发展更多什么。后面经过不断的尝试与努力,自定并拿下二个大方向:运营管理后台与大数据。运营管理后台属于劳动密集型开发,要求团队能沉得住气,做到延迟满足,能在团队开发到二到三年,成长肯定是脱胎换骨的,汤总确实也做到了,表示祝贺。然后大数据方向,当时对我们来说是全新技术,希望能以时俱进,加强研究与应用,找到新方向。技术包括:搜索、推荐、排行榜、活动、业务大数据(当时还未知数据湖名词)等,对应的技术还是挺先进的,业务上也有很大的发挥空间,够我们玩三年(也确实做到了,核心成员全部稳定三年以上,给后面搞大事业打下了基础,正所谓指哪打哪)。并再次制定了行动指南,全组学习大数据技术,进行了为期1.5个月的密集研究与分享活动,效果还是挺不错的,从此正式拉开了序幕,大数据,我们真的来了。当时研究的技术如下。
1、以我为首的搜索研究小组,研究搜索引擎ES技术,最终取得应用与落地,见上一篇文章;
2、以露爷为着的Hadoop+Hive研究小组,研究Hadoop及Hive的应用,并最终结合公司大象数据平台,落地了HIVE的应用;
3、以光神为首的实时计算Flink技术研究小组,研究Flink实时计算技术,在公司推出Flink平台后,我们也完全落地应用;
经过1.5个月后的研究与分享,我们团队基本具备了大数据开发能力,当时有种:“面朝大海,春暖花开”的喜悦; 有种:“东临碣石,以观沧海”的壮志; 有种:“俱往矣,数风流人物,还看今朝!”的气势。所以对于前面历史背景达成的结论,我们也还挺愿意接受的,山芋就要变成黄金甲,从此正式拉开我们团队的奋斗史与创业史。
总体架构
经过多年长期开发、实践与积累,最终形成了如下总体架构,对于涉及公司内部系统名称,名字做了一定的变化(公司比较多对外分享,找下Qcon等技术峰会,可以知道更多细节,或者你假装叫我面试,我可能也告诉你一二个名词)。
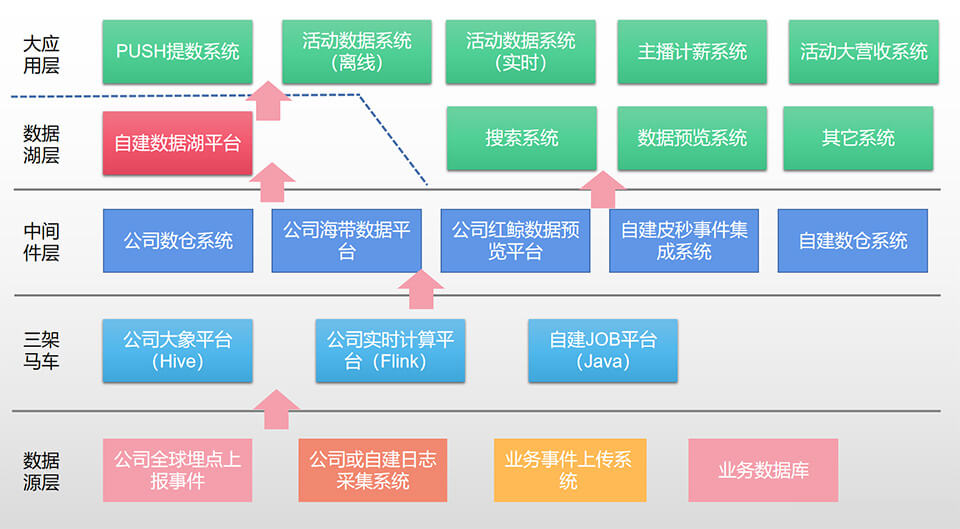
下面将从低层向高层,挑些点来跟大家一起分享,分享目录如下。
1.1、底层数据源
1.2、三架马车
1.2.1、公司大象计算平台
1.2.2、实时计算平台(Flink)
1.2.3、自建Job调度平台(Java)
1.3、中间层
1.4、数据湖
1.4.1、亿级PUSH提数系统(离线)
1.4.2、亿级活动数据系统(离线)
1.4.3、亿级活动数据系统(实时)
1.4.4、主播计薪系统(亿级)
1.4.5、营收大活动系统(亿级)
1.4.6、搜索系统(亿级)
1.4.7、数据浏览系统
1.1、底层数据源
数据采集简单点分享,特别注意点是:全球数据合规问题,如数据落地哪里,保存多久,那些数据要脱敏(像UID),要做到心中有数。但其实好多国家也没有严格执行,我们数据大部分回新加坡,数据通道有走HTTP,有走TAF,也有走Kafka,最后都可以走Kafka,Kafka事实上成为我们大数据系统的一个标准通道。
1.2、三架马车
大数据平台一定离不开计算,所以选择合适的计算框架或平台,是非常关键的一步。通过多年的开发与积累,开发或整合了三个技术平台,这里叫三架马车。使用最多的是:公司大象计算平台(Hive),与自建的调度平台(Java),其次是Flink实时计算平台。Flink技术先进,能进行并行计算,但维护难道大,出问题不好处理,已经在放弃的路上,除事件类Flink代码外,业务计算部分已经大部分迁移到自建调度平台。下面将分别就每个计算平台的优点、缺点或特点做些分享说明。
1.2.1、公司大象计算平台
像AWS或阿里云都有提供EMR计算框架,就是Hadoop这一套,但开发与维护Hadoop Job还是有难道的,要自己处理什么Map/Reduce这些,相信效率也不会提升到那里去。但公司自研了一套,基于Hadoop+Yard平台,面向Hive的Job任务调度平台,用户只需编写Hive SQL即可。我个人感觉还是挺不错的,在WEB页面上直接写Hive的SQl(搞数据湖时也跟他们打通API提交作业),然后配置任务的执行时间,多个任务还可以配置依赖关系,计算完后,数据可以输出到Hive, Mysql, Kafka, Cache等,基本满足了我们的开发需求,我们在该平台有超过6万的调度任务。
1、公司大象计算平台,提供WEB页面直接写HSQL,如一个简单的导数据任务就是一条HSQL语句:
use bigdata;
select mid, rank, watchTime, roomId
from bigdata.dm_push_001 where dt='${tdate?string('yyyy-MM-dd')}' and group_id = 'last_30days_50watch_top_anchor';
2、接着定义任务的运行时间、前后置条件、输出类型等,个人认为最有个性的是触发与依赖,如下图就是一个任务依赖树(专业名词又叫血缘关系)。
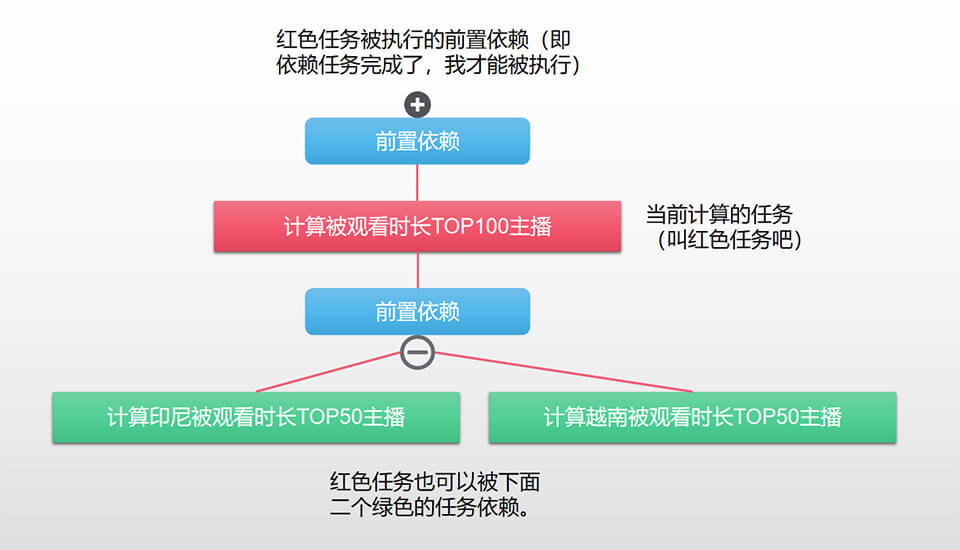
这个任务依赖树,功能还是挺强大的,可以根据自己的功能灵活配置,如可以配置出下面二种情况:
1、红色任务执行完,立即触发二个绿色任务,这个相当于二个绿色任务继承了红色任务的执行时间,它是被触发的;
2、红色任务仅是二个绿色任务被执行的条件之一,如绿色任务配置了9点执行,就算红色任务8点就执行完成,但如果绿色任务设置的其它条件没达到,它不会被执行,或者它等待所有条件完成了,才会被执行。
3、输出类型。可以是空输出(里面还是可以写数据到Hive,像返回void的函数,函数里面也可以写数据到其它地方),或到HIVE,Mysql,Redis,Dcache等数据源,数据可以流向不同数据源,对大数据开发者挺友好的,点赞。
使用这个平台,无需学习Hadoop,仅学会Hive就能写复杂大数据任务,个人认为也是这个平台的能成功的最大优点之一,把复杂的Map/Reduce任务变成更简单易懂的SQL任务,至少普通的程序员能轻松开发了。我也受这个设计思想影响,数据湖更是推进了一步,把写SQL任务变成界面配置就能自动生成SQL,也即不用关心SQL了,这样产品与运营同学都能使用了,虽然本实现方案通用性差点,但在特定场景下,确实也是一个伟大的创新实践,至少推进了人类的一小步吧。
但考虑到写SQL(非自动化实现类),在程序员鄙视链中,低Java几个级,甚至PHP程序员都能鄙视一下,写多可能会吐,所以我要求全组技术全部能写Hive SQL,这样,谁也鄙视不了谁,而且还能保持新鲜感,混着写吧,又能做到相互备份,发现SQL里隐藏的问题(七八个JOIN表,问你怕不?),像计薪的Hive语句,都要二个人相互review,效果还不错。
1.2.2、实时计算平台(Flink)
在制定行动指导时期,就已经着手研究Flink实时计算技术,并内部小范围使用,等公司部署了Flink平台后(跟开源版一样),就开始尝试使用FlinK来写大逻辑实时计算,主要是考虑到如下优点:1、数据降频技术; 2、数据窗口; 3、数据聚合计算; 4、Flink的并行计算; 5、流式代码开发流程; 6、可视化的管理页。但同时也存在一些缺点,如维护困难,出问题不好处理,简要分享点如下。
下面就结合优缺点与它的实际应用场景做些说明。
1、数据降频技术。
这个场景使用非常多,如订阅了某Kafka事件,共有1000万条数据,但仅有10万条数据是符合我们要求的,这里可以使用过滤技术,用flink把kafka的数据进行一次过滤,再把过滤后的kafka数据传到真正的业务系统,对业务系统进行降频减压。
DataStream<SomeModel> filterDataStream = kafkaData
.filter(new FilterFunction<SomeModel>() {
@Override
public boolean filter(SomeModel model) throws Exception {
//仅处理送礼事件
return model.isGiftEeventType();
}
}
).setParallelism(2);
又如,用户给主播送礼物的时候,有一个连击功能,单击1次送1钻石的礼物,连按了100次,则有100条记录,如果业务系统对每条记录都进行100次计算,会比较耗性能,这里可以使用flink把整个记录按时间窗口或数量进行聚合,如单个用户给主播送100次,到达业务系统的仅有一条记录(但礼物数量已经求和),这也是一个比较广的应用场景。
stream.
.windowAll(<window assigner>)
.reduce|aggregate|process(<window function>);
//如每次对1000条数据进行处理,按某种规则进行聚合后,再把数据转向下一层(未考虑数据不够1000的情况)
//这里简单说明用了全局窗口,像上面的场景可以按主播id进行数据聚合
kafkaData.countWindowAll(1000).process(new ProcessAllWindowFunction<SomeModel, NewSomeModel, GlobalWindow>() {
@Override
public void process(ProcessAllWindowFunction<SomeModel, NewSomeModel, GlobalWindow>.Context context,
Iterable<SomeModel> iterable, Collector<NewSomeModel> collector) throws Exception {
//对数据按某种规则进行聚合,再传到下一层
return;
}
});
2、数据窗口。
这个场景使用也非常广,如我们开发了非常多的活动系统,就有这样的功能,如五分钟内给主播送100个钻石的用户给他奖励一个头框,转换成Flink技术就是,按五分钟一个窗口来进行聚合求和,如果条件达到100个钻石,则调用外部系统触发奖励。类似的产品功能还是非常多的,如果用常规的JAVA技术来实现,还是比较难的,但用Flink技术,就是几行代码,所以搞活动我们搞得这么快是有道理的。然后窗口技术支持的形式也比较丰富,如滑动窗口,翻滚窗口,全局窗口等,还有丰富的函数,新手会喜欢上这种编码方式,特别是那些被复杂窗口需求折磨过的同学,甚至会情不自禁的说声我操。
//直接看官方文档demo,是个不错的选择。
//https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/learn-flink/streaming_analytics/#windows
input
.keyBy(x -> x.key)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.reduce(new MyReducingMax(), new MyWindowFunction());
3、数据聚合计算。
这个功能点,上面其实已经说明了,可以按窗口对数据进行聚合等各种计算,如求和,求平均值,计数等等的功能,也可以实现自己的功能函数,更丰富的功能可以查看文档。
4、Flink并行计算。
并行计算,个人感觉还挺强大的,考虑下面的数据处理流程,假设一共有6步:1、数据输入(重); 2、数据过滤(重); 3、数据转换(轻); 4、数据按字段分组与开窗口(轻); 5、对数据进行处理(重); 6、数据输出(轻)。假设第1、2、5步工作是忙的,如需要占用4个CPU,但第3、4、6步工作量比较轻,如占用1个CPU就行。下面图示对比一下串行与并行的二种方案。
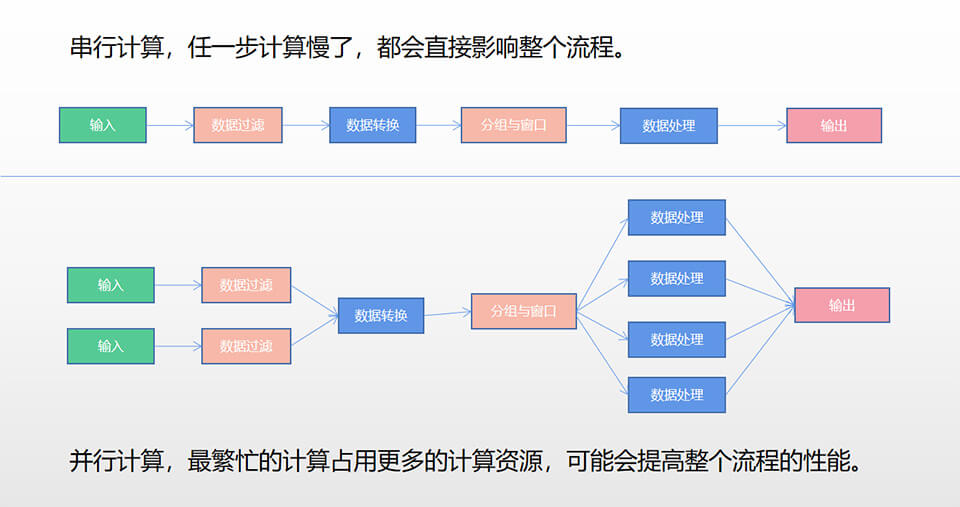
如果使用普通Java来针对某部分单独进行并行计算处理,还是挺难的,但Flink就是几个API(setParallelism),伪代码见下面。
inputkafkaData
//过滤数据设计2个并行度
.filter(new MyFilterFunction(...)).setParallelism(2);
//数据转换设置1个并行度
.flatMap(new MyFlatMapFunction(...)).setParallelism(1);
.keyBy(x -> x.key)
.countWindow(...).trigger(...)
//最忙的程序设置4个并行度
.process(new MyProcessWindowFunction(...)).setParallelism(4);
//输出设置1个并行度
.addSink(MySink(...)).setParallelism(1);
最后,顺便提醒一下,并行计算仅能说是理论上的快,是否真快要给合实际场景。如很小的数据量,就没有必要这样搞。如不合理的使用多个Jobmanager,就存在跨机并行调度问题。如不合理的使用多个并行度,就存在并行梯度变化等。像这种情况都有可能变慢。
5、流式代码开发流程。
这个跟Jquery的连式API有点像的,跟JAVA8的Stream API也有点像,可以流式调用输入层,中间处理算子层,输出层,使用程序表达得更清晰。如我们的实时活动,就分输入层,过滤算子,转换算子,积分计算子,输出层,结构层次还是比较清晰。
6、可视化的计算流程。
Flink计算平台,本身提供有管理系统,所以你在系统里能直观的查看相关数据。如数据流动的方向与步骤,已经处理的条数,运行时间等,这种直观的可观化图,对管理人员来说是一件好事。
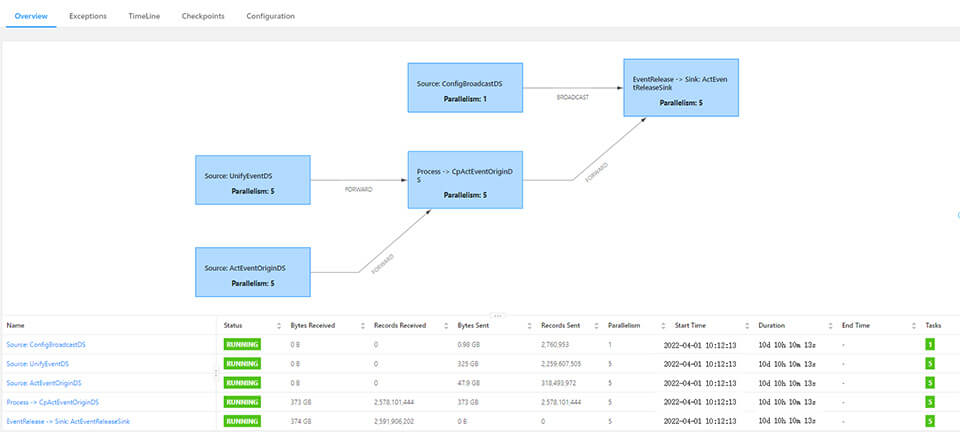
说了这么多Flink的好处,其实它的缺点也挺明显的:
1、Flink有一定学习难度,工作交接不容易,特别是初学者,得花一段时间学习、研究与理解,像slot,并行度,算子啊,这些新行为与概念跟原来的普通Java编程不同。
2、并行计算与执行带来的问题复杂度,对解决问题不利。如日志可能是乱序的,你得知道那个程序在那个算子运行,特别是算子多,并行度多的时候,找起问题一不小心就乱了。
3、Flink组件接入不方便,如接入redis或mysql等是件不容易的事,像Spring框架放进来,也会影响性能,特别是IO组件操作多的话,性能会变得更差。
也正是上面这些原因,当我们玩够Flink后,除了对事件的集成与整合部分,其它的业务代码,已经慢慢开始放弃,改成普通的Job调度。
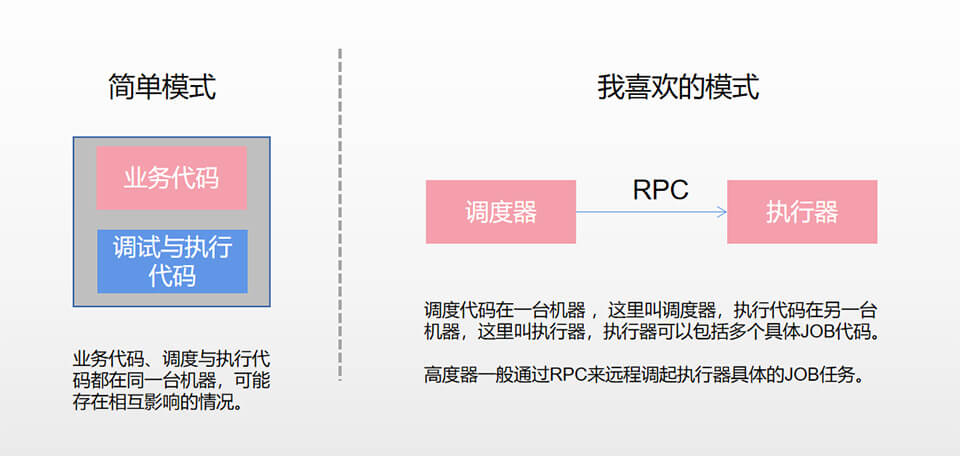
1.2.3、自建Job调度平台(Java)
这几年,用到的调度器技术挺多,如直接使用Java原生的Timer或Thread,但如果是多机部署,得考虑同一份代码在多台机器同时执行的问题,使用不当,可能出现问题。另外调度任务重的话,可能会影响其它同服务器代码性能。而且调度与业务代码混写的话,对于频繁发布也是一个问题。
我提倡调度与执行相分离,上面的原生技术明显不符合这个规则。然后用了Quartz类库,当时比较有名,特别是支持cron表达式,改造后可支持上传JAR,实现调度与执行相分离。后来用唯品会的saturn。但总感觉是有点复杂,不方便开发与维护。后来一次团队讨论,光神同学推荐xx-job,感觉总体设计思想不错,就拿来改造,并在海外团队大面积推广使用,年调度超过50亿次,总体比较稳定,符合预期。
改造xx-job的时候,发现它最新版本的任务是基于方法级别的,也就是说一个类定义N个方法的话,可以对应N个任务,但旧版本是一个类对应一个任务。以我的经验起见,一个类对应一个任务才是合理的粒度,太细太粗都不好,所以从它的老版本2.1进行了改造,改造点如下:
1、增加公司安全帐号登录;
2、原来的管理页统计数据是实时发SQL统计的,如果调度量比较小的话,没有问题,但调度量大的话,一统计就容易锁表,接着引起其它调度异常,所以把统计改成异步一天统计一次的离线方式,管理页查的是统计结果数据,速度超快,后面就再也没出现过问题;
3、每天定时删除90天以前的调度日志,减少数据库压力,永远不会爆数据库;
4、调度算法进行了部分优化,如上一次未执行完成,下一次又来了,这样策略怎样处理,我这里增加直接跳过处理;
5、禁止脚本语言执行调度,因为这样很危险,随便一个错误的脚本,如shell脚本,可能执行删除服务器操作;
6、增加按执行器与任务级别的关键字报警策略或缺失调度报警,这个还是挺重要的,出现问题马上能及时短信报警;
7、对UI页面进行了小调,更适合我们团队的使用风格。
8、增加了一个通用的HTTP调度器,即可以通过平台配置任何基于Http的定时远程调度,对一些后门程序或拨测程序非常友好;
9、增加了一个基于公司TAF协议的RPC远程调度接口,方便配置TAF定时器服务;
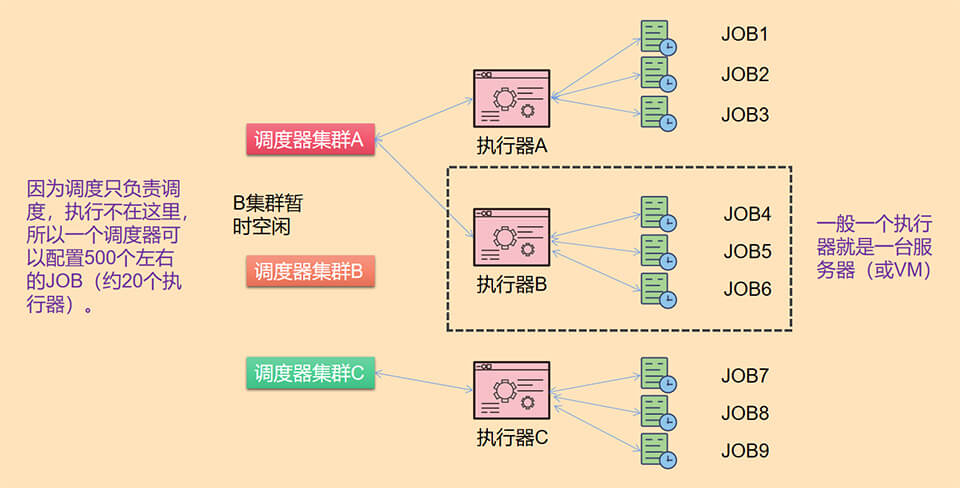
调试器根据业务的不同,可以像下面这样分组部署,既可以做到一定的相互独立,互不影响,也可类聚代码,方便管理,如下图。
1.3、中间层
因为这部分会涉及公司的专有系统,不具备通用性,先简单用一节全部简介完,大概了解他们的功能即可,如果感兴趣的话,可以到云平台看下,应该也有类似产品,在做方案时参考一下。
1、公司数仓系统,可以理解成一个存放中间结果表的集合,如一堆Mysql表或一堆Hive表等,数据仅对程序员开放。
2、公司海带数据平台,主要是二部分,第一部分:报表平台,如核心报表,给大BOSS看的; 第二部分:提供了一个编写SQL的页面,给产品或运营自助提数(下载成文件);
3、公司红鲸数据平台,主要提供一个平台,给用户查看law数据,个人感觉,这个系统的作用是让用户知道有什么数据,后面才可以搞数据。平台提供了一个比较友好的数据格式解析界面,像JSON,表格数据都能友好展示。如看APP埋点事件,这个平台不错;
4、自建皮秒事件集成系统,主要是把各种各样的Kafka事件,清洗成具有统一格式的kafka数据(全字段),为什么这样做,因为统一事件后,能在同一个地方写上一堆通用的处理程序,提高开发效率。
5、自建数仓系统,因为我们做排行榜,做活动,做推荐等,需要很多数据,所以我们也搞了一个小规模的数仓,主要存放各类大宽表,内部也经常从这里调数据,也属于数据湖的一部分。
1.4、数据湖
什么是数据湖?数据湖跟数据仓库有什么区别?有时候,团队同学也会问这样的问题。那什么是数据湖呢?来一个粗定义:就是一堆数据的集合,可以是结构化的,也可以是非结构化的。如可以是像Mysql这样的表数据,也可以是像Redis这样的缓存数据,也可以是Json数据或者文件。数据湖的数据访问频率更高,经常存取,而且像大海,湖泊一样,流动性很强。最后容量很大,一眼望不到边际,有容乃大。如诗句:“衔远山,吞长江,浩浩汤汤,横无际涯,朝晖夕阴,气象万千”。而且还具备数据自加工的能力。按我理解整理的一些点如下:
| 区别 | 数据湖 | 数据仓库 |
|---|---|---|
| 1 | 数据格式不限,多样化 | 一般来说是结构化的数据 |
| 2 | 数据读取频率更高,使用广泛 | 读写频率低,一般用来做报表展示 |
| 3 | 具备数据加工能力 | 一般没有 |
当然,你如果感觉,这样的区别还是太难理解,那你就认为他们是一样吧,也问题不大(我们也学习过部分阿里或AWS提供的数据湖实践分享讲座,同学反馈很虚,犹如空中楼阁,听完后,知道了S3或OSS,但数据湖怎样搞,还是一头冒水)。看一下我们数据湖的全局图吧,说不定你看完也是一头冒水,不过没有关系,只能求同存异,我们也是特定场景下的一个实现。
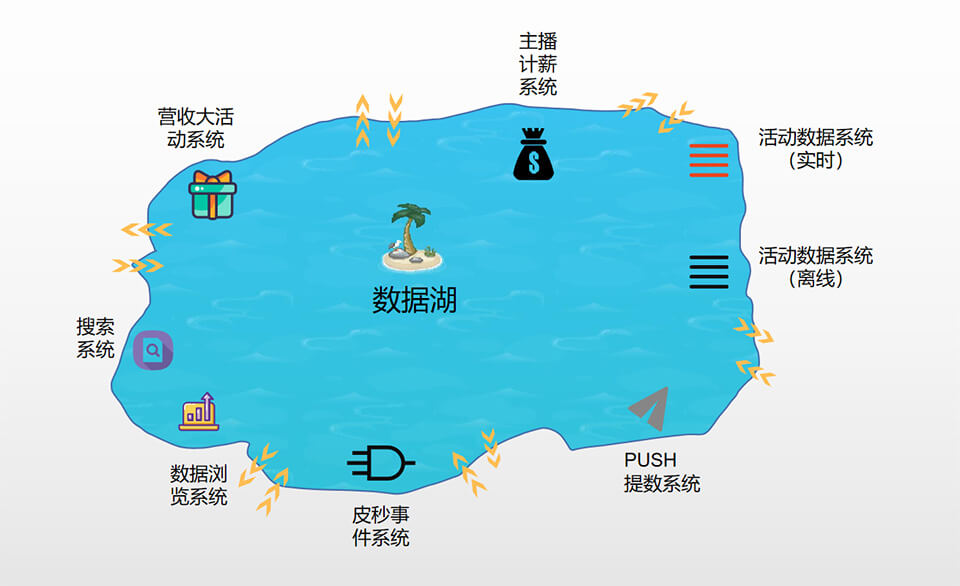
从上图可以看到,数据湖里建起了不同的应用,数据在应用间流入与流出,或者又具备数据加工能力,是不是有点像深圳前海周边的码头加工厂啊?也正在这些应用的存在,使得数据湖变得有价值,下面就谈一下我们的应用实战吧,可能这些应用的价值比数据湖本身更加重要了。
1.4.1、亿级PUSH提数系统(离线)
先说下PUSH是什么?可以理解成手机APP的消息提醒,好理解,那就开始吧。随着项目慢慢运营起来,PUSH成为了一个重要的推广手段,如主播开播,给他粉丝发PUSH。如大主播开播,给相应国家活跃的用户发送PUSH。如搞大活动,比赛进行时,主播A快要输给主播B了,给双方用户群发PUSH。特别是后面搞营收,感觉到处有PUSH,不知用户有没有反感?应用场景越来越多。但无论业务怎样变,都要拿数据,拿各种不同的数据来发PUSH。
因为涉及到数据,大数据,如果每期发PUSH数据需求都要开发,效率比较低,所以我们每收到一类新需求,开发完后,就考虑抽象成通用的数据任务(Hive),然后这个数据任务每天跑数据(叫指标),然后在管理后台提供一个指标筛选系统,选择各种条件,就能出数据(结果集),这些数据就是要发送PUSH的用户,技术流程如下。
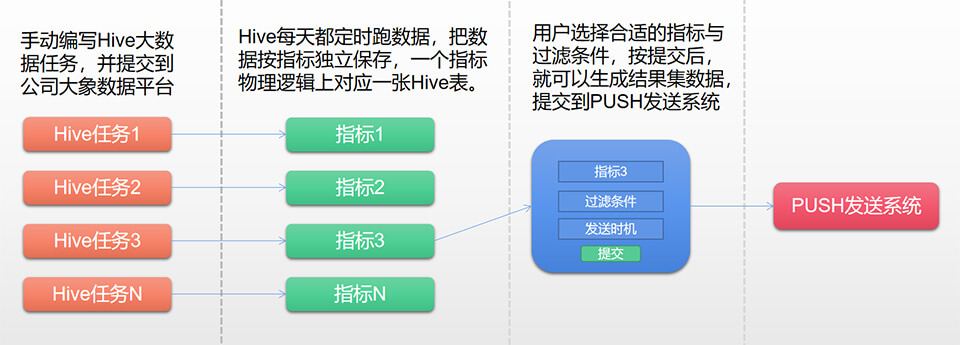
本方案每类数据还是要手写Hive任务(程序员的事),但用户提取数据就简单多了(产品或运营),选择好指标,设置好过滤条件,就能拿到数据发PUSH,效率很高,其中上图的筛选动作,如果翻译成SQL语句,则是:
select uid from 指标 where 过滤条件 //指标设计比较重要
小组同学大概开发了50个指标数据(也有同学喜欢叫大宽表),基本能满足85%的PUSH数据需求,大大节省了人力,但上面方案也存在一些缺点,见下面,也正是这些缺点,驱动我们开发更灵活的活动数据系统,见下小节:
1、字段一般有且仅有一个,uid,而且不支持字段函数,如求和等;
2、每新增一类指标,都要手动编写HIVE任务并上线,HIVE可能是非常复杂的HSQL代码;
3、每天都会跑指标数据,不管这个指标用还是不用,会造成一定的数据浪费(可以手动删除);
1.4.2、亿级活动数据系统(离线)
活动榜单的数据需求比PUSH的数据需求复杂太多,仅靠开发数据指标(像PUSH一样),已经达不到相应的开发效率,我们进行了长达半年的思考与讨论,最终定下可实现的HIVE任务自动化方案(有限性),执行操刀的是露爷,真给力,能明白我想要的效果,最终结果也超我预想。这个系统开发出来后,由产品或运营直接在管理平台通过UI界面配置好组合模板(不用写SQL),数据湖自动生成HSQL,再提交到公司大象平台,任务跑完就有数据(结果集),过程基本完全自动化,关键技术与流程如下。
1、Hive任务模板引擎。
之前也简单提到过,我们已经有很多数据,但要取数据,至少得学会Hive SQL,对程序员来说,还是a piece of cake,但像产品与运营学起SQL可不是件容易的事,所以研究SQL模板引擎,用户在UI界面来点点划划,提交后就能得到相应的数据,这是一个非常伟大的创意,不但提高了开发效率,而且拉近了用户与我们的距离,易用性方面上了新的台阶,一经推广,受到运营同学的极力欢迎,甚至他们计薪数据还在这里手动对账,超乎想象(公司海带数据平台功能强大,但要求写SQL,部分同学不会用,这可能是我们的差异化优势)。
为了说明什么是SQL引擎,先从SQL说起,因为我们的模板引擎最终是翻译成SQL,所以先看一下SQL的构成是怎样的。
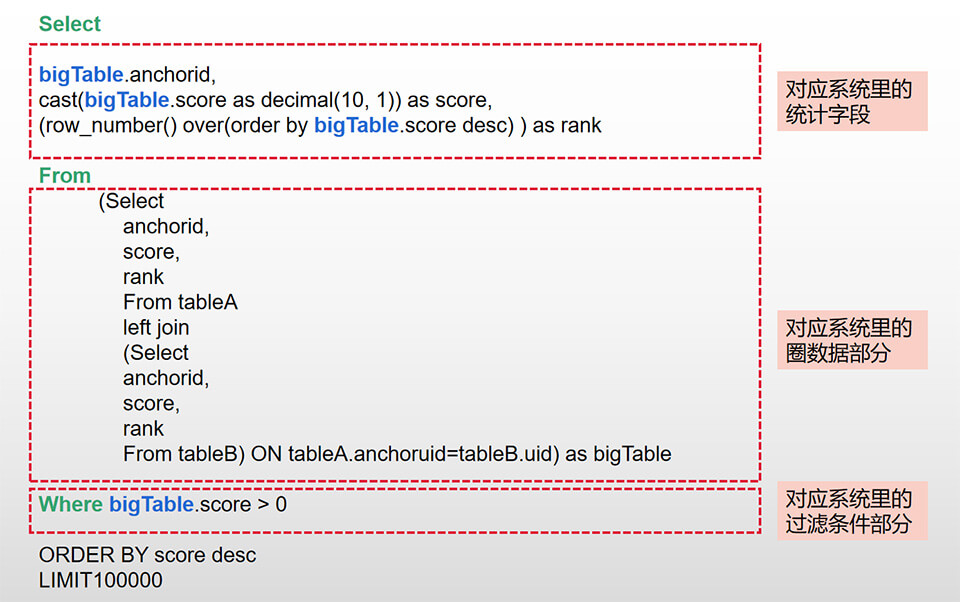
接着就是设计好UI流程与步骤,让用户操作,最终生成上面的SQL语句,伪设计图如下。第一步是选择统计字段,我们做了好多统计字段模板,前期能想到或可实现的都搞了,相当select里的字段部分(其中支持字段子查询这个是比较复杂的)。第二是圈定数据范围,想当于SQL里的表部分,支持left join 和 inner join等模板,前期也想得足够多了,够用。第三部分是过滤条件与新增字段。过滤条件相当于SQL的where语句。新增字段支持表达式计算,挺实用的,因为活动有好多个性的积分计算,就是基于这种设计,简要如下图。
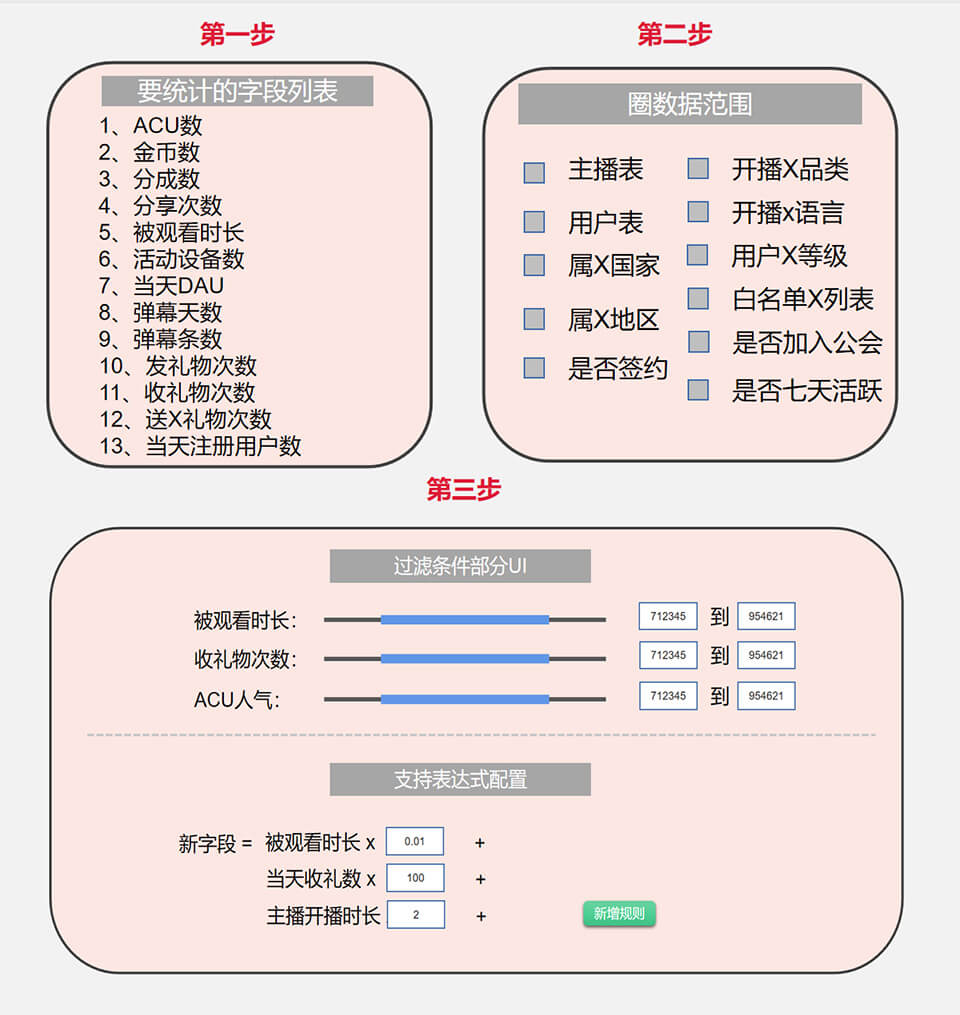
按上面步骤配置,几乎任一个运营同学经过短时间学习,都能速度上手应用,比写Hive SQL容易多了,这也是数据湖受欢迎的原因。
2、离线榜单系统。
上面最重要的问题解决后,接下来的就是整合流程的问题了,如把生成的SQL,再附加上其它的一些信息,如执行时间,与公司大象平台整合(他们默认是支持WEB上写语句,但这次他们提供了API给我们接通),就可以自动创造Hive任务,生成相应的数据后,再接到其它系统或新功能,就能得到完整的解决方案。
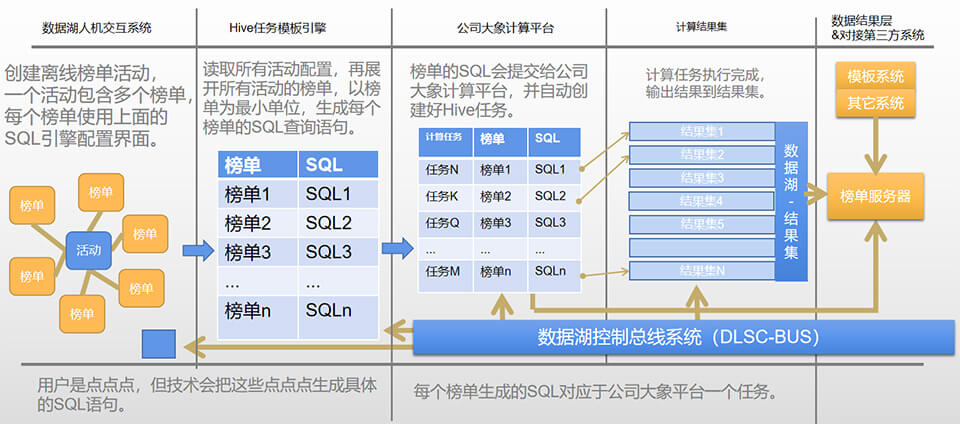
数据湖上线不久,机器自动化编写的Hive任务数就快速破万,比人手编写的二年总和还要多2倍以上,这就是技术革命带来的效率,下面放一张公开的常规活动截图,里面的数据全部是自动配置生成的。
1.4.3、亿级活动数据系统(实时)
上面分享的大数据,基本都是离线形式,也就是说数据不是实时的,正常都是T+1,但实时的数据可能更具吸引力,如用户给主播打赏,如果马上能反馈到排行榜里,这会让人非常心动。其实这种功能,已经支持,但这一类的需求,都需要开发,耗时耗人力,所以得研发实时数据支持系统。
实时数据,主要考虑活动实时数据,如充值数据、打赏数据、用户埋点数据等。但这些数据来源非常复杂,格式又不统一,所以得统一数据格式,专门搞了一个简单的皮秒事件系统,上面搜索系统也介绍过,主要是统一事件后,能用一套事件处理代码,提高开发效率,方案如下:
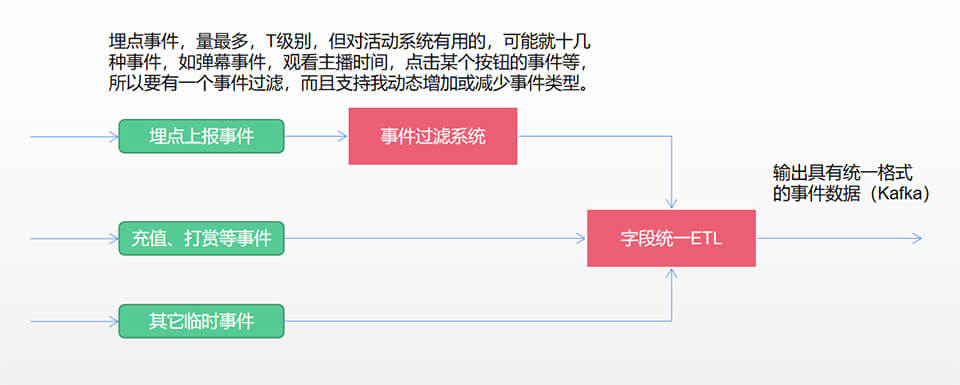
整合了相关的事件(大概整合超30类实时事件),再统一了数据格式,那可以做的事情就多了,除了做榜单排名(类型超级多),还可以搞微型玩法系统、微型任务系统等,这些功能还是非常实用的,一经推出,深受产品与运营欢迎,又创造了价值,大概方案如下。
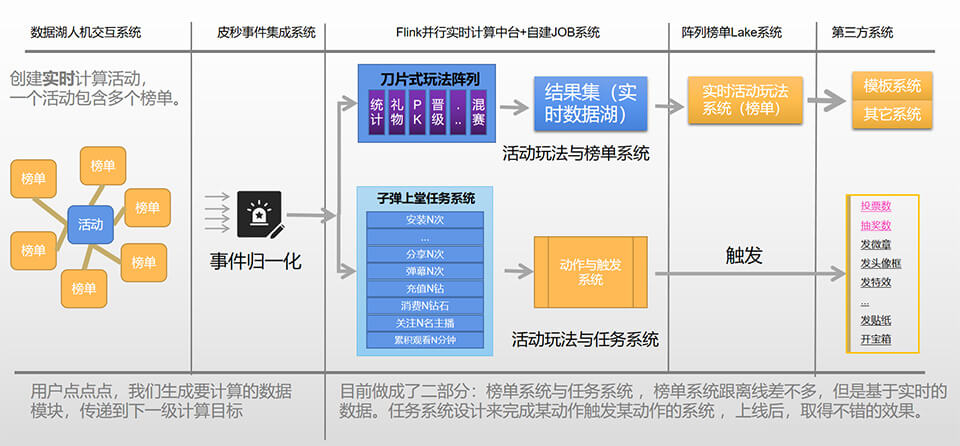
1.4.4、主播计薪系统(亿级)
计薪系统还是非常重要的,给主播打钱、发工资与分成等,就靠这份数据,核心中的核心,对数据质量要求非常之高。计薪系统指标非常多(如开播时长、人气或充值数),指标逻辑复杂。但不管是什么指标,基本都要分时区,分品类,分国家,所以又给计薪程序增加了复杂度。其中对计薪影响最大的是时效与时区问题。首先时效上,计薪数据不能太实时,因为一旦出错,出去的数据很难收回,所以采用了离线T+1形式(但内部又是提前的)。其次是时区问题,每个国家的自然天是不一样的,所以要针对本地区时间进行结薪。
单个指标计算方案大要如下:1、确实基准时间,使用UTC0为基准时间; 2、以每小时出一次离线数据; 3、根据本地的时区对天进行数据聚合; 最后就是数据对账,数据补扣流程,流程看起来不复杂,但实际执行起来,还是挺复杂的,见下面流程:
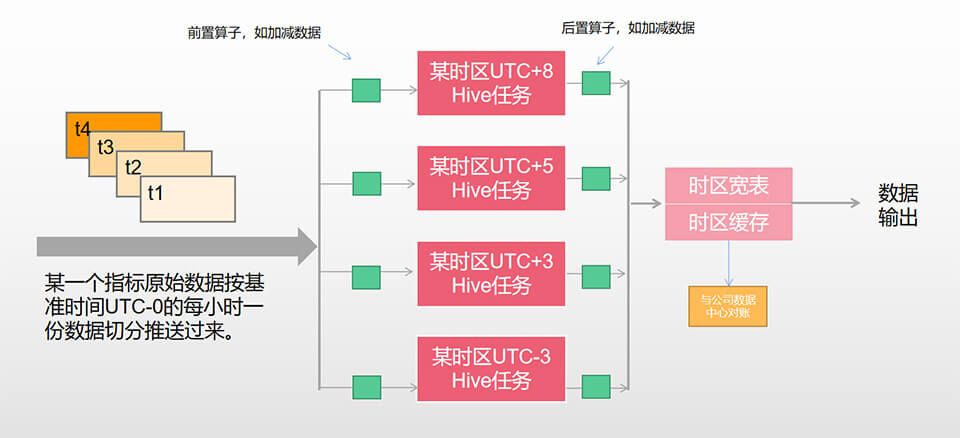
大家可以估算一个任务数咯,如果有10个计薪指标,运营5个时区,则有10 x 5 = 50 个Hive计算任务,所以在开发与维护上,都是有一定难度的(当然我们也搞了一些小工具,先保密),特别是碰到重跑数据,异常流程等,稍不注意,就是大事故,但我们四年零事故,也充分体现了我们的专业性与敬业精神。
1.4.5、营收大活动系统(亿级)
写到这里,感觉有点累了,我都断断续续写了三天,但还是坚持一下吧,感觉快要收尾了,不过你是读者,累了,还是建议你停一停,先饮杯caffe,再慢慢回来品尝。
营收大活动系统,超级无敌复杂系统,核心中的核心,特别是最后二年,充KPI,老板的目标每季一新高,开发压力可以说是压力山大帝,也是整个项目组最忙的团队。先说下该系统的特点,需求变化快,花样太多,开发周期非常短,指定上线时间,每月加数量。我们团队表现优秀,不断思考,不断进化,开发出一堆又一堆的小功能组件,把大活动当成拼乐高,模块化组合,最终,胜利完成最伟大的S级目标,致敬,respect!
不过话又说回来,这么庞大的系统,想三语二言说明白,还得再开一篇文章,那就先说个简单版,知道有这么一会事就行了,如果真有谁十分感兴趣,可以备上53度飞天茅台好酒,再来二盘汕头空运牛肉,我娓娓道来,细节麻,需要时间来讲解。
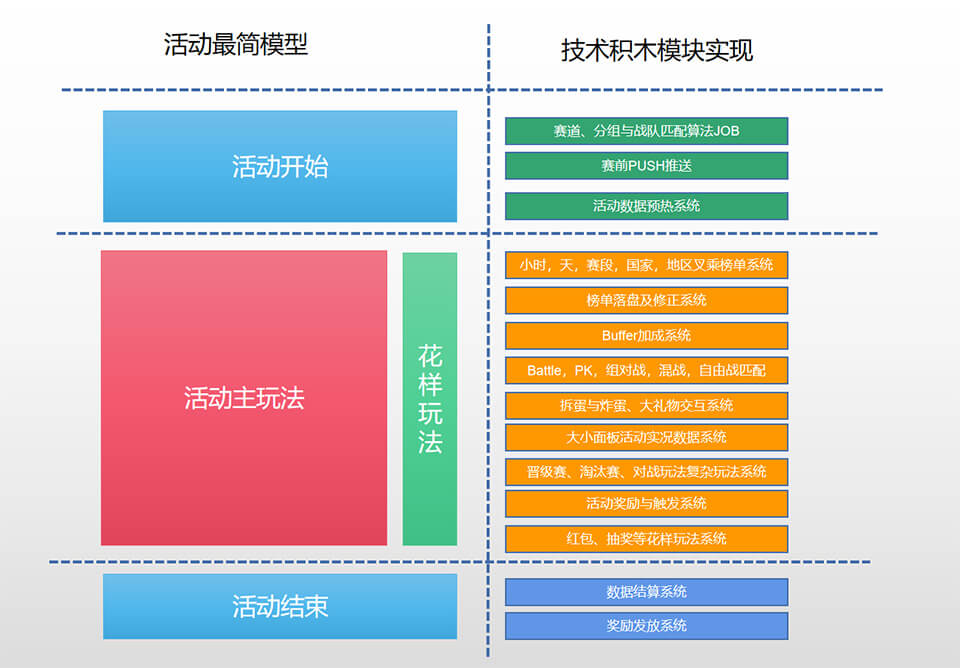
说回大活动,粗分为二部分吧,主玩法系统与花样玩法系统,其实也没有严格的划分,主要是我分任务的时候,就按这种思路来,可能这样写文章也更容易理解。
什么是主玩法系统,就是活动的主体骨架,如晋级赛、淘汰赛、对战赛,逻辑挺复杂的,如被打败的人或战队,要先掉到临时区,但再战猛点,还可以复活,也还可以给土豪打赏救命,是不是很牛B,然后每个赛段,排行榜可能超过1000个(小时榜,天榜,周榜,特定礼物,人,土豪,战区,国家与大区叉乘)。过程还穿插着battle(对战),PK(连米),buffer(送礼得更多积分),语音房等大功能。还有扔拆炸蛋,吸血鬼(赢的一方吸收输的一方多少积分),运营数据干扰,奖励与实时发放,活动实况,过程弹窗,阶段性PUSH发送,还要配合每个国家的风土人情节日(如1、3、7上线,2、4、6下线),确实是无比复杂。
像上面这样的节奏,搞了2年多,积累的东西也越来越多(但确实也有效,因为营收节节上升,也不得不服)。产品功能多了,交接是一块大问题。如每次产品换人大清洗(互联网就这样),新来的交接产品,都是上气不接下气来了解旧功能,心生可怜之情。其实呢,我也比较担心技术交接与传承问题,所以组内也经常做交叉互备开发,果然,担心什么来什么,2022年,过年前的二个月,正是KPI大冲刺阶段,一起走过3年多的露爷被挖走,在这种千钧一发的时候,备选级人物(俊司令)挑起了前进的大旗,一夫当关,勇往直前,胜利完成任务,确保历史的前进步伐从未停止(也兑现我的承诺,组内任一人离开,不影响核心流程开发,包括我),有点扯远了。
什么是花样玩法系统,名字很高大上,其实可以理解成,跟大活动玩法相对独立的玩法,不走晋级,不走淘汰,活动期间一直可以玩。如活动期间拆炸蛋、扔炸蛋、捣乱搞鬼,红包,抽奖,邀请等,每期活动基本重用,这里就不再展开,去玩下某应用就知。
下面整个活动的简单架构图,但不求你能看明白,有时候难得糊涂也是一种美。
1.4.6、搜索系统(亿级)
搜索系统也属于大数据系统的一部分,该技术的引入与应用,壮实了团队的技术力量,突出了团队的业务价值,其实刚开始是应用日志搜索系统,等技术研究成熟后,孵化应用到首页搜索系统,是一次成功的实践与尝试。
详情见:亿级别搜索系统架构与总结
1.4.7、数据浏览系统
数据浏览系统还是有必要的,一般来说,程序员喜欢直接用命令在终端显示数据,但当数据复杂的时候,或者要临时显示报表时,有适当系统支持会达到事半工倍的作用。我们修改了另公司的一个半开源产品(组内同学带来的),支持非常强大的SQL编写来展示数据,还是挺不错的。最初,给运营搞了约300张报表,就是这个平台来展示,受到好评,后面不搞报表后,用作内部调试用。当然公司也有比较强大的报表平台,但因为涉及到非常复杂的权限问题,只有正式的数据展示才会用。如有感兴趣,可以参考一下云产品,简单的需求。或自建grafna或phpmysqladmin系统做数据展示。
总结
写完了,终于写完,应该已经超过1.6万字了,敲了三天,不知有几个人能读完,不过无所谓,如诗:二十四桥仍在,波心荡,冷月无声,念桥边红药,年年知为谁生?先知为我生,相信后面会蜂蝶自来。不过,趁现在有时间,先写下来吧,也许过了N年,适同学少年,再次相聚,又能想起共同的回忆,那段不忘初心,牢记使命,勇攀高峰,再创佳绩的奋斗历史。那段造了数亿数据,拿下S级营收目标,稳住计薪四年零事件的难忘经历,运营与分析组精神永存。