原创精品,请慢慢品尝,手机阅读体验也不错!大屏电脑放大到125%阅读效果更佳!
写在前面
曾任某直播公司,海外直播部,主导搜索系统的开发工作。从刚开始的主播搜索到后面的用户搜索、直播间搜索,游戏搜索等,从5个搜索字段到后期的三十多个字段,数据规模也从100万到亿级别,技术上由原来简单的数据库Like查询,到纯缓存查询,再到最后的复杂ES搜索系统。在搜索相关性方面下了功夫,如分词、粗排与精排、搜索联想、搜索纠错与推荐等。在高并发大流量方面也做了精细化的优化,如融断、并行搜索、多级缓存技术等,接受了瞬间50倍流量峰值考验。还要接受产品与运营无比复杂的需求迭代开发。结果也表现优秀,产品影响因子0.25,技术指标A或S级,三年零事故,特别难。过程还是挺深刻的,也成就了该成就的人或事,积累了一定的经验与技巧,借些机会用来分享,希望你喜欢。
温馨提示:为了不与具体业务相关联,对数据进行了脱敏或假设处理,也就是说本文章不涉及公司的具体业务与隐私。
搜索关键点
搜索可以说是无处不在咯,如平时使用的百度搜索,点点鼠标就得到想要的结果,感觉是一件非常普通的事情,但让技术重新实现,那可不简单,最难的莫过于,搜索相关度问题,就是用户的搜索是他想要的吗?是否符合要求,为了更好的理解用户需求,我们要思考怎样进行清洗与抽象(这里我叫它特征提取),甚至用AI技术来得到满意的结构化数据,得到结构化数据后,就得考虑怎样设计索引,然后就是搜索,我们从搜索引擎Elasticsearch(下面简称ES)得到的数据是粗排,然后进行精排与过滤(这里叫召回),接着是数据缓存等等一大堆功能,一个像样的搜索系统,有点像下面的样子,要自成体系。

下面就对涉及的功能点,进行技术性展开,分解列表如下:
1.1、为什么选择ES作为搜索引擎
1.2、什么是搜索并行技术?
1.3、多级数据缓存技术
1.4、热点数据加载机制
1.5、亿级别增量数据索引技术
1.6、融断机制
1.7、AB-TEST搜索方案
1.8、搜索相关性
1.8.1、分词技术
1.8.2、搜索纠错系统
1.8.3、搜索评分方案
1.8.4、搜索联想技术
1.8.5、数据精排系统(数据召回)
1.9、辅助推荐系统
2.0、数据清洗技术应用
2.1、技术指标、日志与监控
1.1、为什么选择ES作为搜索引擎。
ES功能完善,提供多语言API接口,生产环境可以使用Java API,然后调试或测试可以使用Python语言,非常方便,然后ES提供详细的使用手册或文档,特别是提供kibana管理平台,对数据管理非常友好,下图是kibana的样本截图。

1.2、什么是搜索并行技术?
这里的并行搜索技术,不是指ES的多节点并行搜索技术(当然,公司有钱的话,节点越多,性能越好),而是指业务上的并行搜索技术,如某场景:输入一个关键字,我们要搜索:主播库、用户库、直接间库、游戏库、小视频库等约5个的ES索引库,有二个实现方案,如下图。
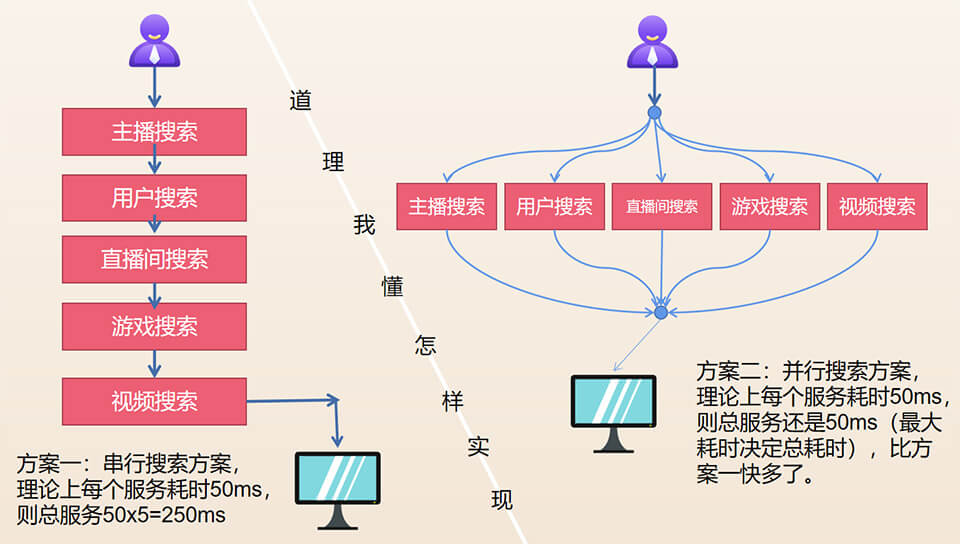
上图的理念还是挺简单的,但怎样实现可能会让你感到困难。
方案一:ES索引库串行搜索方法,假设单个搜索耗时50ms,则5个搜索耗时是50x5=250ms,下面是2个并行搜索的伪代码实现如下。
public SearchResult search(SearchCondition searchCondition){
//搜索结果
SearchResult searchResult = new SearchResult();
//1.先搜索用户
Result userResult = esSearchService.searchUser(searchCondition);
searchResult.add(userResult);
//2.再搜索主播
Result anchorResult = esSearchService.searchAnchor(searchCondition);
searchResult.add(anchorResult);
return searchResult;
}
串行实现起来简单,但当有多个索引库时,耗时可能达不到要求,所以得采用下面的搜索并行技术。
方案二:ES索引库并行搜索,技术上采用Java的Fork-Join线程模型,总耗时理论上就是耗时最大的那个耗时,响应比方案一快多了,伪代码如下:
第一步:定义好并行执行的线程池:
@Bean("searchExecutor")
public ExecutorService getSearchExecutorService(){
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(100, 10000, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(500));
threadPoolExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
threadPoolExecutor.setThreadFactory(new ThreadFactory() {
int count = 1;
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "search-executor-" + count++);
}
});
return threadPoolExecutor;
}
第二步:定义好并行执行框架代码:
public SearchResult search(SearchCondition searchCondition){
//搜索结果
SearchResult searchResult = new SearchResult();
//创建并行执行器
List<CompletableFuture> completableFutures = new ArrayList<>();
//并行搜索用户
CompletableFuture<Void> userFuture = CompletableFuture.supplyAsync(() -> {
Result anchorResult = esSearchService.searchAnchor(searchCondition);
searchResult.add(anchorResult);
return null;
}, searchExecutor);
//并行执行相关超时设置
TimeoutCompletableFuture<Void> timeoutGameFuture = new TimeoutCompletableFuture<>(TimeUnit.MILLISECONDS, futureTimeOut, userFuture);
timeoutGameFuture.orTimeout();
completableFutures.add(userFuture);
//并行搜索主播
CompletableFuture<Void> anchorFuture = CompletableFuture.supplyAsync(() -> {
Result userResult = esSearchService.searchUser(searchCondition);
searchResult.add(userResult);
return null;
}, searchExecutor);
//并行执行相关超时设置
TimeoutCompletableFuture<Void> timeoutGameFuture = new TimeoutCompletableFuture<>(TimeUnit.MILLISECONDS, futureTimeOut, anchorFuture);
timeoutGameFuture.orTimeout();
completableFutures.add(anchorFuture);
//最后一步,等所有并行处理完成后,再统一返回结果。
CompletableFuture.allOf(completableFutures.toArray(new CompletableFuture[]{})).join();
}
1.3、多级数据缓存技术
一个高并发大流量的互联网系统是离不开缓存技术的,搜索系统也不例外,本次架构了3级数据缓存(包括ES是4级),缓存技术给我们带来了太多的优点与好处。如海外某大主播开播,在Facebook等平台发广告,然后用户疯狂来搜索,峰值流量甚至是平时的50倍,是不是很吓人,但本系统是那个三年从没挂机的黄金指标系统,就凭这一点,又赢得了吹牛B的风采。
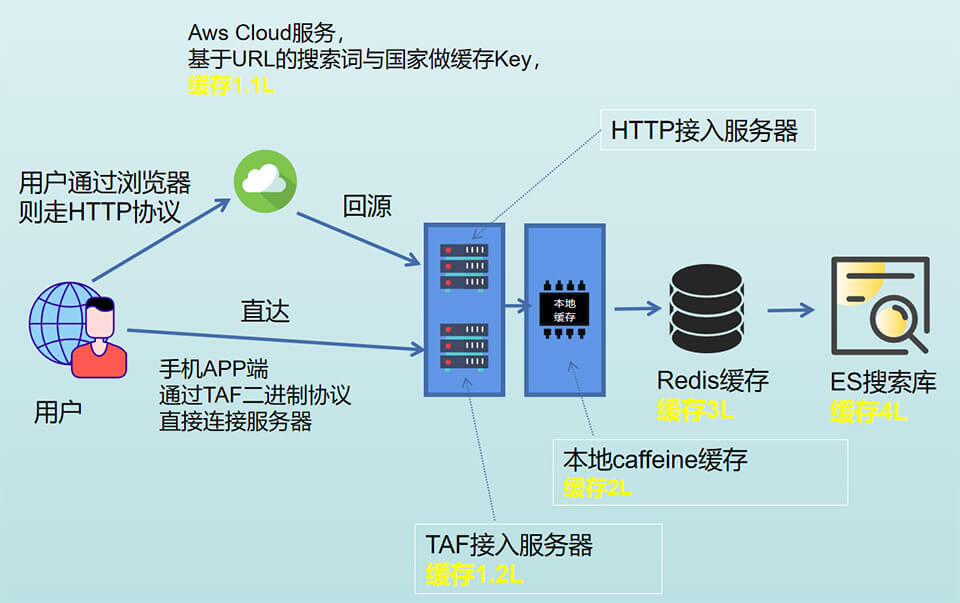
从图中可以看到各缓存,其中缓存1.1L是基于CDN的缓存; 缓存1.2L是TAF接口网关配置的缓存; 这二个有平台提供配置支持,其它缓存都是由程序来控制(除掉ES的L4),一共是3级。其中缓存2L,我们使用caffeine开源框架,对缓存控制非常不错,是非常关键的部分,缓存2L伪代码如下。
@Bean(value="anchorCache")
public LoadingCache loadingCache(){
return Caffeine.newBuilder().initialCapacity(DEFAULT_MIN_SIZE).maximumSize(DEFAULT_MAX_SIZE).recordStats().
expireAfterWrite(DEFAULT_EXPIRE_TIME, TimeUnit.SECONDS).build(new CacheLoader<SearchCondition, SearchResult>() {
@CheckForNull
@Override
public SearchResult load(@Nonnull SearchCondition searchCondition) throws Exception {
//这里调用下一级数据,就是没有缓存到的数据
return dosomething(searchCondition);
}
});
}
1.4、热点数据加载机制
海外直播,经常搞活动,如大主播开播,热点数据要提前加载,在主播开播时或特定时间如晚上12点,使用调度器或程序,自动循环加载数据到缓存,减少大活动繁忙时期外部IO调用,方案不复杂,大家脑补一下就行。
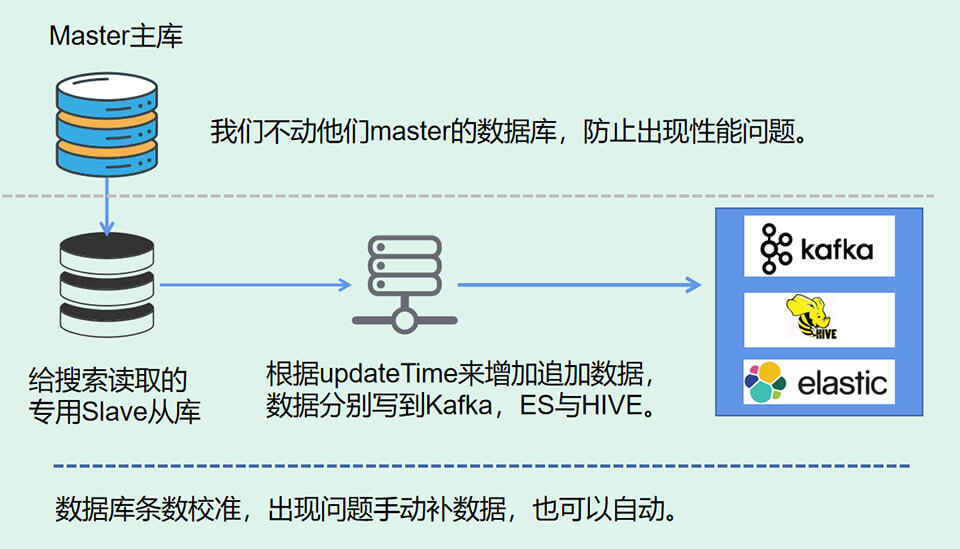
1.5、亿级别增量数据索引技术
用户注册由另一个项目组负责,数据交互,涉及到跨小组开发与合作,为了体现我们的专业,我们没有直接去全量读取他们的mysql数据库(亿级别),我们得增量去读取(没有使用mysql_log),而且不能把造成锁表,最终定了如下方案,其实不难:
1.6、融断机制
本系统涉及的组件或数据源比较多,如调用ES搜索服务器,调用用户详细信息服务器,调用推荐数据服务器等,每一步都有可能失败,有些失败可以加异常机制来解决问题,但有些失败不好处理,如整个用户服务器挂了,如整个Mysql或Redis数据库挂了怎样办,其实说真的,除了快速恢复相关服务,我们也没有办法,但真发生了,我们有应对措施(或者跟老板说,这一切都在掌控之中),采取被动策略,即服务降级或融断,给用户提供默认准备好的数据。

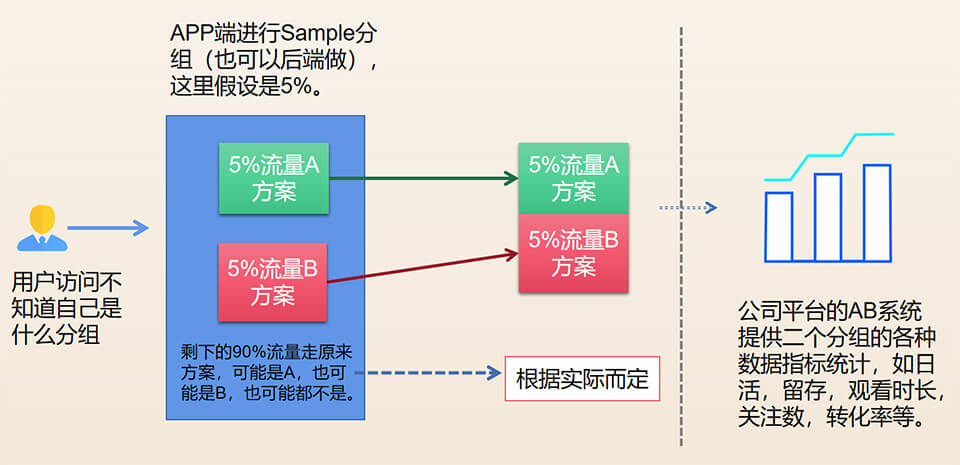
1.7、AB-TEST搜索方案
新出的搜索需求效果怎样?特别是那个超级复杂搜索需求,除了上线后观察,谁也不好提前评估出效果,仅能做的就是拍脑袋,看那个产品大佬或老板叫得响或信心更足,然后选择做那个方案,但AB测试方案理论上提供了一种更合理的拍脑袋方案,因为有数据支持,所以上线这套系统是合理的,情理之中。但实际运行情况来看,效果不算太理想,可能产品的对比方案本身就差不多,体现不出对比度。剧透下,某段时间,搜索的AB方案,B方案就比A方案高了7%的留存率,相关同学已经高兴到手舞足道(算是AB测试在搜索系统的一次成功应用),哈哈,先看下AB粗简流程吧。
1.8、搜索相关性
搜索相关性是搜索系统里最关键也是最难的部分,但直播行业的搜索跟传统的搜索又是有区别的,直播行业的搜索可能更加垂直,更加专注,主要关注点在主播、用户或直播间的搜索,而不是通常的长篇文档数据搜索,而正是这种相对较短的字符串数据,而且是结构化的数据,给我们在相关性搜索上又有发挥的空间,那我们就开始进入吧。
1.8.1、分词技术
什么是分词?分词就是把一句话或一段文字切分成字或词为单位的切分技术。ES搜索引擎就是基于词的搜索,如用户查询主播名字的时候,输入:“zhang san li si ?”,得到的分词是:zhang、san、li、si四个分词,然后拿4个分词去搜索引擎里查找,如下图所未。
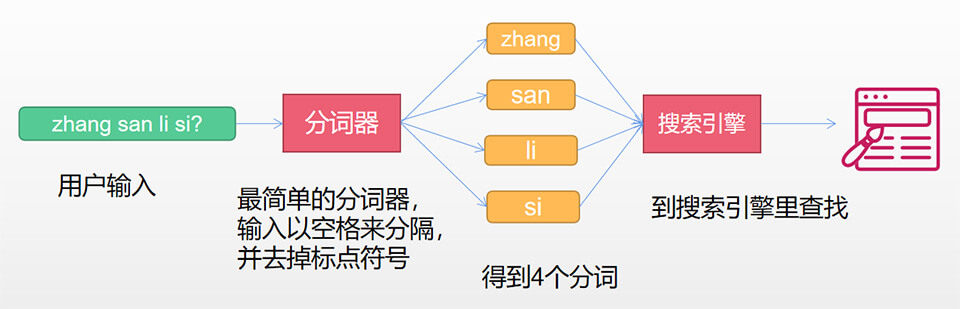
如果我们的数据库里有一个名叫:“zhang da zui”的人,因为输入与姓名都有相同的分词zhang,所以这个人会被搜索到。那么如果数据库里这个人名叫"zhang3 da zui"呢?会被搜索到吗?不会,因为名字里的zhang3跟输入里的zhang是不匹配的,多了一个数字3。
这时候,你可能就有疑问了?zhang3明明包含zhang啊,为什么查不到?这就是词匹配的可爱之处,zhang3与zhang是二个不同的词,当然就不相等了。那有没有类似包含搜索呢?是有的,ES搜索引擎也提供类似Mysql的like查询,如fuzzy,prefix,regexp等,但如果是亿级别的数据,真的这样做吗?这样做性能真的不太好。
上面就是我们面临的问题一,其实还有问题二,请看下面的描述。
不知你也有发现,一篇正常的短篇小说,可能有上千成万个字或词组成,所以按词来索引并搜索是合理的,但我们是直播行业,我们搜索的是ID,姓名,昵称这种短语或短句,按正常的理解,他真的没有包含多少字或词,如某主播叫:Miss king,按正常分词得到二个词:Miss、king,也就是说,你必须输入Miss或king才能找到她,这样用户肯定不干了,他们想输入mi、ing、iss或miss max都能找到我,所以我们的分词得拆分够细来支持这种查询。
最疯狂的分词器,来吧,就是对名字、昵称等短句,直接按单个字母来分词,这是什么概念,如名字:Miss king,会被分成6个词:M,i,s,k,n,g,单个字母作为一个词,虽然有一点点性能损耗,但实际运行起来,确实完美解决了上面的问题一与问题二,特别又完全兼容最短搜索匹配,perfect!
分词说到这里就完了吗?没有,还有一些要注意的点,我总结一下:
1、姓名或昵称没有停止词,像英语里有“This is zhang san”,这里的This可能就是停止词,因为停止词在搜索里无什么意义,我们搜索时,关心的是zhang san,This与is都不会关心,但姓名与昵称就不同,特别是外国人的名字千奇百怪的,所以是什么就保留什么吧,在这里没有停止词,一切都是有用的。
2、ES提供了强大的自定义Token分词与过滤器,除标准分词器,还有大小写转换过滤器,禁用词过滤器,语法转换过滤器等等,学习搜索引擎相关书籍时,还有自定义过滤器的例子。想象下,自己写了一个可以过滤HTML标签的过滤器,如把:<div><p>zhang san</p></div>变成zhang、san二个分词,又或者写了一个字母映射的过滤器,cool,我猜,这时候,你正拿起一杯coffee,看着外边人来人往的世界,再加上窗边落日的余辉,想着以后财富自由的生活,真是太美了,但是,请打住,你千万不要太草率的使用过多这样的过滤器,除了使用一些基本的过滤词外,如果可能,请用其它程序处理好分词,再把数据传进来,后面小节有例子说明。
3、个人简介、直播间简介或游戏简介这种长文字的,用默认的空格分词策略也好,得看你具体业务,像文章搜索,建议词或词组来分词,如百度分词这样,效果可能会更好。
1.8.2、搜索纠错系统
上面已经提到,使用自己的分词过滤器时要三思,用它千万不要太复杂,影响性能,除了这点外,不用它也有另外的原因,就是项目的可维护性。首先,相对于ES,使用Java预处理数据改起需求更简单,JAVA团队,人人都会写JAVA,但ES就不一定了,是有专人负责。其次,像业务规则,可能时时变,如果是JAVA,你想怎样改就怎样改,为所欲为,但ES就不同,分词除在搜索时使用外,数据存储索引的时候也用使用,错误的分词会影响底层的存储结构,就像保存了错的数据,修改起来非常困难。
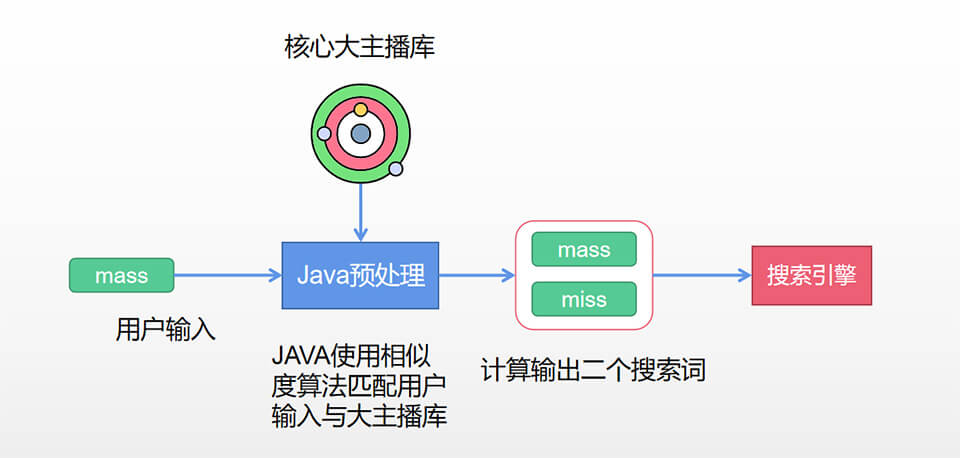
但说曹操,曹操就到,产品要求有一个搜索纠错功能,如大主播miss,经常被同学错误输成mass,按目前规则,可能搜索不到该用户,或者搜索到的数据不是用户想要的。怎么办?又提出了新的解决方案,我们把用户的输入与预定义好的大主播库进行相似度计算,如mass,经过计算,得到与他相似的miss,然后我们把二个词同时传到搜索引擎去查找,那肯定就能找到miss这个人,而且也能解决用户真想输入mass的问题,顺手把运营人员指派的关键字搜索需求也鲁了。
但这种纠错功能,不是使用es分词,而是JAVA代码,下面是程序方案:
1.8.3、搜索评分系统
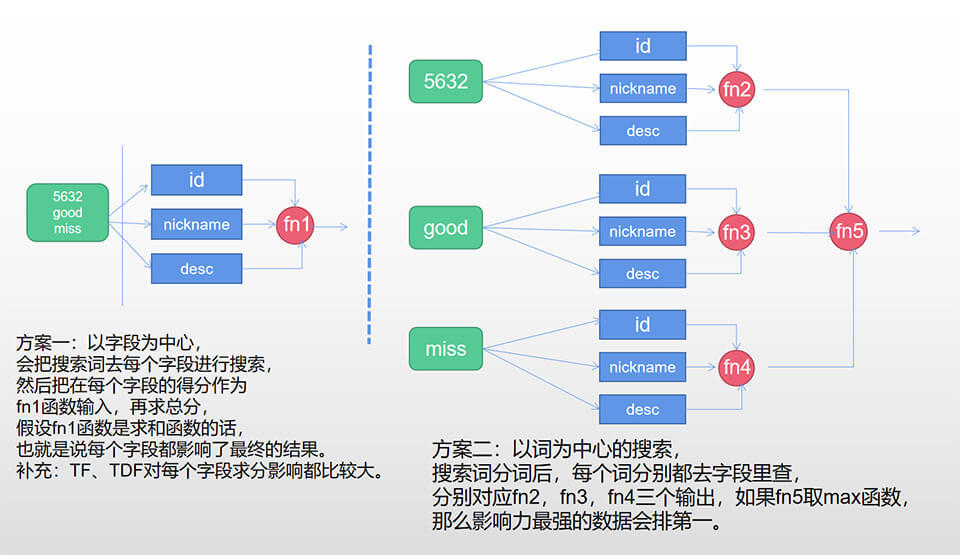
用户搜索的时候,压根不管是搜索用户ID,昵称,姓名还是简介等,反正你给我返回我想要的内容就行,但技术实现的时候,得考虑怎样找到用户想要的东西,也就是内容评分系统,是怎样评分的?怎样排序的?技术上有term精准匹配,还是match匹配,fuzzy模糊匹配等,还有以字段为中心的搜索方案和以词为中心的搜索方案。要深入搞懂这些,你得读读ES文档,但这是一往篇讲架构的文章,先略去它,就讲下实际的一些做法吧。
1、精确匹配放大技术。如用户输入的是:568784,这样的一个字符串,假设能精准匹配一个用户的ID,同时也能匹配另一个用户的简介,那么,准确匹配用户ID的数据要排第一,这就是放大器,如放大100倍,那他肯定就排第一了,伪代码如下。
"query": {
"multi_match": {
"query" : "568785",
"fields" : ["id^100", "nickname^10", "desc"]
}
}
2、评分方案选择。每种方案都有它的优秀与缺点,没有标准答案,如精确匹配,各种组合查询(boolean、dismax、boosting),根据实际情况而用,但,这里强调一下,以字段或与词为中心的搜索思想,对指导实际开发有参考价值,如海外直播,以精准匹配,组合或以词为中心的搜索方案为主,看下字段与词为中心的搜索方案对比吧。
3、查询过滤器对评分的无影响。查询过滤器对字段评分不产生影响,而且适当使用它还能提高性能。以实际场景为例,用户搜索主播时,搜索词是:"miss Vietnam",那么层底搜索逻辑是:搜索昵称包含miss的主播,而且国家是Vietnam,假设初衷是,希望昵称字段对评分产生影响,但地区字段不产生影响,那么就可以使用查询过滤器机制,把主播国家字段放到过滤器里。如果把查询过滤器前置,也可能提前减少了数据量,对提高性能有一定帮助,伪代码如下。
"query" : {
"filtered" : {
"query" : {
"terms" :{
"nickname" : ["miss", "max", "good", "man"]
}
},
"filter" : {
"term" : {
"country" : "Vietnam"
}
}
}
}
评分系统主要是上面三点,其实,实际开发,这块的代码挺多的,我们组的开发小妹,有事无事就调下这些代码,希望能发现最佳组合,最后可以关注一下查全率与查准率,甚至还得关注下AI技术,反正为了满足用户的需求,还有很多工作可做。
1.8.4、搜索联想技术
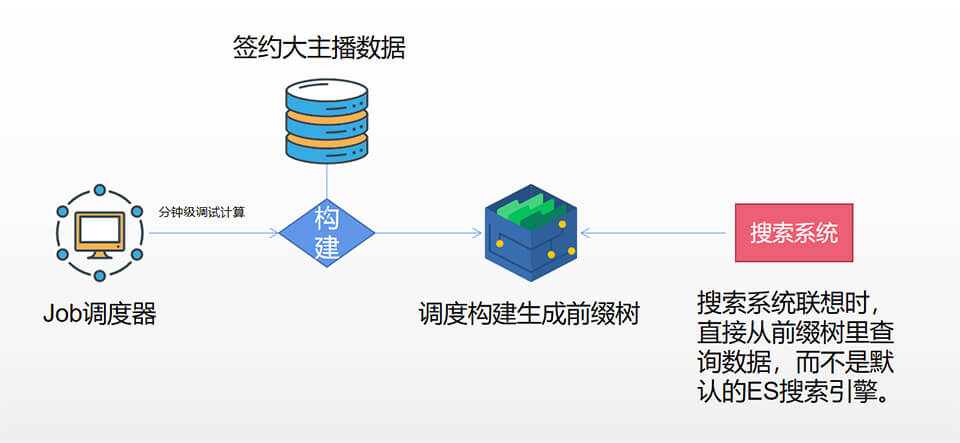
ES是支持complete suggester,但考虑到我们doc数量比较太大,直接用,性能消耗应该很大,不适合于直接对外的互联网系统,成本可能也更高,所以我们自己实现了相应的输入联想技术,我们不对全量数据进行联想提示,仅对有价值的部分,TOPN的开播主播实现联想提示。
1.8.5、数据精排系统(数据召回)
除了搜索,还有排序,如搜索到数据后,还要满足产品上的各种排序需求,如要按在线状态,粉丝数,直播间人数,充值数,所在国家,开播时长,特权,管理后台指派等各种各样的指标进行排序,如果把这些排序全部放到搜索引擎来做,也不太合实际,第一是增加了业务的复杂度,第二评估性能也不会太好,所以还是开发了基于业务的精排系统。
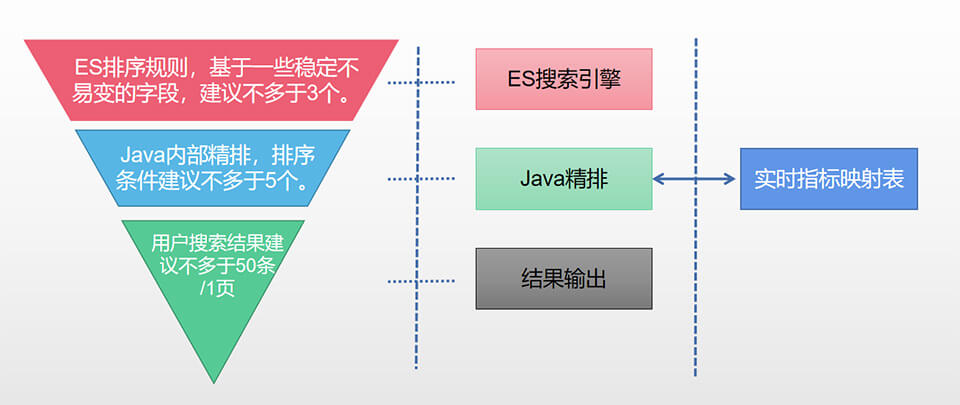
主要流程大概如下:首先使用搜索词到搜索系统里查找一定数量的记录,如1000条,然后再拿这1000条的数据,给精排系统进行各种基于内存的排序或过滤,在做好缓存与分页的情况下,可能给用户返回的就是50条一页,因为涉及到一些实时状态,如直播间人数,充值数,点赞数等会动态变化,所以我们获取这些信息时,搞了一个用户实时状态快照,总体流程如下图。
1.9、辅助推荐系统
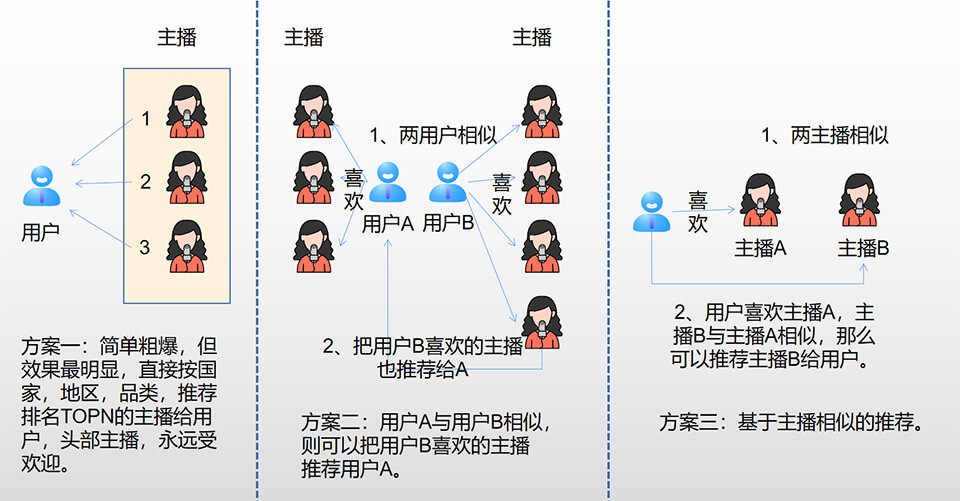
除了搜索,还有推荐,ES引擎也是支持做推荐系统的,但不太灵活,我们实现了一个更简单的推荐系统,如当用户搜索不到内容时,或者搜索指定推广直接间时,我们使用搜索+推荐。当然,推荐系统知识点好广,感兴趣的可以单独学习,这里实现个三种小方案,分别是直接人气推荐、基于用户相似性推荐、基于主播相似性推荐,如下图。
2.0、数据清洗技术应用
数据清洗技术不属于搜索技术的范围,但任何有点价值的系统,都离不开数据清洗技术,特别是复杂的垂直行业搜索系统,要清洗非常多的离线或实时数据,给搜索系统做指标,而且这部分的工作量还不少,特别是ELK清洗程序,要紧跟业务方对接,流程如下图。

2.1、技术指标、日志与监控
技术指标:接口成功率,包括服务端成功率与客户端成功率,服务端成功率就是服务端能正常响应的成功率,表示服务端是好的。客户端成功率就比较严格,表示客户到服务器这个连路是否有问题,如使用APP时,网络稍有波动,成功率就会下降,但这种全链路监控也能更好发现问题。
自定指标:接口耗时,表达了程序性能问题,方便同学优化程序。
业务指标:自定指标,如点击率,业务贡献率,产品对技术的满意度等,希望技术与产品打成一片,一起把事情做好。
日志监控:自己实现的日志级别的监控与报警系统,一旦有异常,或日志里有打印有报警关键字或心跳异常,马上报警。
公司平台:公司对全链路跟踪提供了强大的指标监控,有什么风吹草动,我们能马上知道。
总的来说,监控报警还是非常充分的,但要保证指标优秀,就得看人了,看平时工作互备情况与团队内部合作能力如何,我们组同学给力啊,连续二年,核心黄金指标全部A或S级,真是超级无敌难,想起那多少个夜晚,大家一起远程连线排查这种那种的反馈(海外与中国睡觉时间不同),确实付出了很大心血。
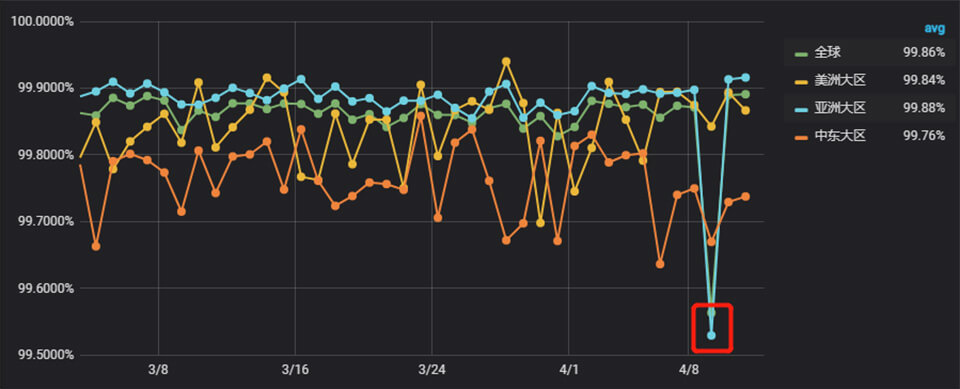
如果你们对上面监控感兴趣,公司又没有完善的监控平台,可以搞套ELK+Grafna+Hbase+Kafka+ClickHouse,往往也有意想不到的效果,这个项目开始也是这样搞的,下面是一张Grafna监控样图,曲线还是比较直观好理解。
总结
不知不觉,写了二天,文章也超过了1.2万字,手都敲到麻了,不过搞出这套系统就更加不容易,罗马不是一天建成的,搜索系统,也让我们持续开发与维护了三年,我做框架,团队做开发,从零开始,确实不容易,不过也成就了相应的人或事。如搜索系统作出了应有的贡献,产品贡献率是0.25,非常的高。如每次推广大活动,搜索系统都发挥最坚实的支持,都能顶住2-50倍的流量压力,三年零事故,黄金指标A或S级,也给团队赢得了风采。如产品或开发成员也拿到了回报。又是一次成功的项目实践体验,值了。最后以此文献给原来团队,为公司创造了价值,你们辛苦了。