写在前面
本文编写于2024-04-19,最近2026-03-28进行了重新编辑,主要对内容进行压缩,去掉了跟业务有关的文字,由原来PDF排版改成网页排版。内容是基于某广告消耗统计系统的实际案例,分析了在业务侧将数据更新频率由每日一次调整为每小时一次后,导致查询结果出现大幅波动的情况。简单点说就是,在更新过程中存在新旧数据混合的中间状态,对数据查询造成了干扰。在低频更新或数据量比较小的情况下,该问题很难暴露,而在高频大数据更新情况下,如果更新过程与查询发生重叠,导致用户读取到不完整或会产生误导的数据,也叫数据抖动问题。针对该问题,本文提出了一种基于 Apache Doris的数据防抖动技术,主要是通过结Unique Key模型与分区替换机制,实现数据计算与数据查询过程的隔离,在亿级数据查询条件下也实现数据的稳定性与一致性。
1. 结论(Conclusion)
在大规模数据处理系统中,合理利用 Doris 的临时分区(Temporary Partition) 与 Unique Key 数据模型,能够显著降低数据更新过程中产生的数据抖动问题。
在亿级数据规模下,该方案具备如下工程价值:
- 有效避免数据更新过程中的中间态被用户读取
- 提高系统查询结果的一致性与稳定性
- 降低数据更新期间的业务风险
- 提供更加可靠的数据观测能力
本文从实际业务场景出发,分析数据抖动问题产生的根本原因,并逐步介绍多种常见实现方案,最终给出基于 Doris 的工程化解决方案。通过对方案演进过程的系统性说明,读者可深入理解该技术在大规模数据场景中的实践价值。
2. 背景(Introduction)
在 2023 年 9 月的一次生产运行过程中,业务系统出现了明显的数据波动现象。具体表现为:
- 在 11:00 查询某媒体广告消耗数据时,结果约为 1000 万美元
- 在 15:00 查询同一数据时,结果约为 400 万美元
- 在 19:00 再次查询时,结果约为 1500 万美元
上述数据虽为示例数值,但其变化趋势表明,在不同时间点查询同一业务指标时,系统返回结果存在显著差异。该问题原来并没有存在,也就是这几天经常出现的事情,通过上线日志发现,最近数据更新策略发生了变化。原来系统每天 07:00 执行数据更新任务,而业务人员一般在 09:00 之后查询数据。所以9点前,即使存在数据变化的中间状态,但也不会被用户感知,系统整体表现稳定。
随着业务需求的变化,数据策略在近期进行了调整:由每日更新一次,改为每小时执行一次更新任务。经深入的技术排查,就是这个问题引起的:数据更新过程中中间状态被用户读取,从而导致数据可见性不一致。
基于上述分析结果,团队启动了针对数据处理流程的优化工作,重点目标包括:
- 提升数据更新过程的稳定性
- 减少用户可感知的数据波动
- 保证查询结果的一致性
本文将对该问题的形成机制以及最终优化方案进行系统性说明。
3. 问题原因分析(Problem Analysis)
数据抖动问题的本质,通常来源于:数据更新过程中的中间状态被用户读取。
在对数据执行以下操作时:
- 新增(Insert)
- 删除(Delete)
- 修改(Update)
不同时间点查询同一数据,可能得到不同的计算结果。在数据规模较小的情况下,该问题通常不易被观察;但在百万级或亿级数据规模下,该问题会被显著放大,并可能影响业务决策。以下通过若干典型场景进行说明。
3.1 被感知的数据更新过程
假设某广告主在广告平台投放广告,并每日产生广告消耗数据。在一次数据更新过程中,系统可能执行如下操作:
- 删除 2 条错误归属数据
- 新增 3 条新的归属数据
- 修改 2 条已有数据
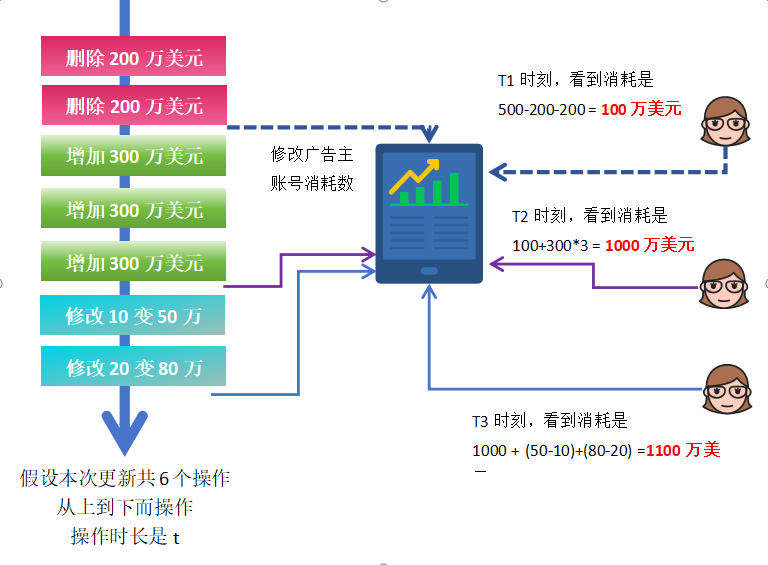
假设初始余额为:500 万美元
在执行上述多个操作过程中,如果用户在不同时间点进行查询,例如:
- t1
- t2
- t3
则可能分别观察到如下结果:
- t1:100 万美元
- t2:1000 万美元
- t3:1100 万美元
虽然最终余额为正确值,但由于查询发生在不同阶段,用户可能在更新过程中观察到不一致的数据。
当数据更新耗时较长时,该问题将更加明显,并可能导致业务层误判。
该现象说明:能被用户感知的数据更新中间态是数据波的原因。
3.2 数据更新顺序不一致
在分布式系统中,数据处理顺序往往无法严格保证一致,假设上面的数据,顺序乱了,按下面的数据顺序来到达(主要是数据依赖的Kafka是异步消息)。
如果调整新增与删除操作的执行顺序,则可能得到另一组查询结果:
- t1:1400 万美元
- t2:1000 万美元
- t3:1100 万美元
虽然最终结果仍然一致,但中间阶段的数据差异依然明显。
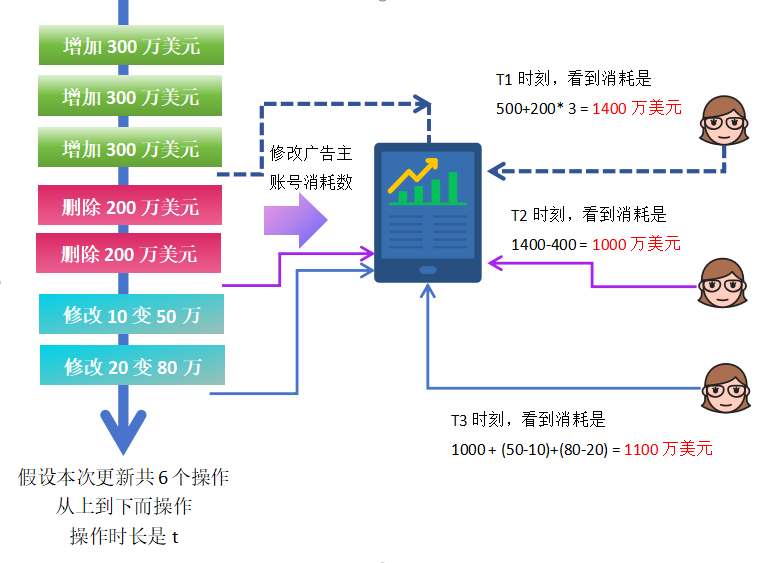
该现象说明:数据执行顺序的不确定性是数据波动的原因。
3.3 重复消费数据造成误差
在消息队列系统(如 Kafka)中,如果消费逻辑未进行严格控制,可能产生:
- 数据重复消费
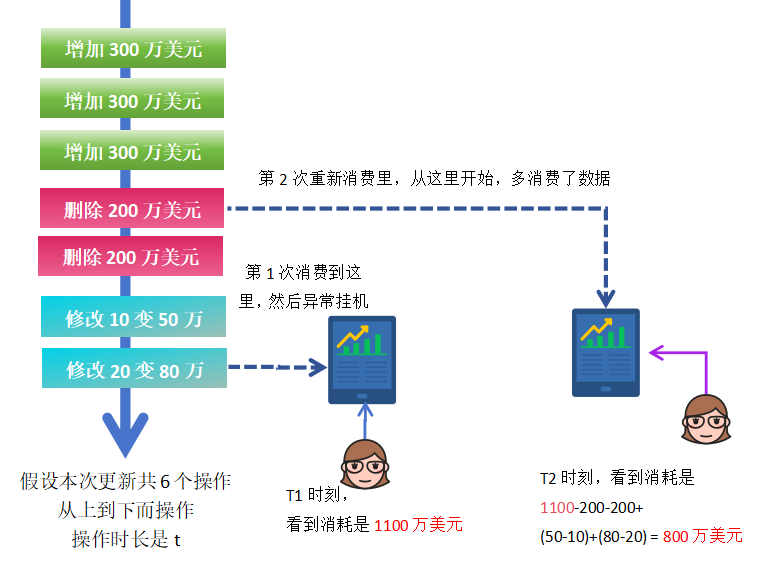
因为程序异常挂机,造成Kafka偏移量不正确,从而导致数据重复累积,最终造成数据异常增长。
4. 常见实现方案(MySQL 版本)
在理解数据抖动问题产生机制之后,有必要先分析传统关系型数据库(如 MySQL)中的常见处理方案,为后续 Doris 方案提供对比基础。
4.1 基于版本号的数据替换方案
该方案通过引入 版本号(Version) 字段,实现数据更新控制。
假设初始数据如下,同时分配版本号 Version = 1:
| 广告主 | 投放地区 | 消耗金额 | 消耗日期 | 版本号 |
|---|---|---|---|---|
| 11111 | US | 100 | 2024-04-20 | 1 |
| 11111 | UK | 200 | 2024-04-21 | 1 |
| 11111 | SG | 100 | 2024-04-22 | 1 |
第二天系统从外部接口获取到新的数据,数据如下表所示:
| 广告主 | 投放地区 | 消耗金额 | 消耗日期 |
|---|---|---|---|
| 11111 | US | 100 | 2024-04-20 |
| 11111 | UK | 300 | 2024-04-21 |
| 22222 | IN | 100 | 2024-04-22 |
此时:
- 原有 SG 数据被删除
- UK 数据金额发生变化
- 新增 IN 数据
更新流程如下,首先写入新数据,并带上版本号 version=2:
| 广告主 | 投放地区 | 消耗金额 | 消耗日期 | 版本 |
|---|---|---|---|---|
| 11111 | US | 100 | 2024-04-20 | 2 |
| 11111 | UK | 300 | 2024-04-21 | 2 |
| 11111 | SG | 100 | 2024-04-22 | 1 |
| 22222 | IN | 100 | 2024-04-22 | 2 |
随后删除旧版本数据,这里是删除version != 2的数据,最终得到:
| 广告主 | 投放地区 | 消耗金额 | 消耗日期 | 版本 |
|---|---|---|---|---|
| 11111 | US | 100 | 2024-04-20 | 2 |
| 11111 | UK | 300 | 2024-04-21 | 2 |
| 22222 | IN | 100 | 2024-04-22 | 2 |
该方案的优点是逻辑清晰,但在更新过程中仍可能出现数据短暂不一致。
4.2 全量删除后重新插入方案
另一种简单但风险较高的方案为:
DELETE FROM table;
随后重新插入全部数据,该方案在执行过程中,系统可能出现:
- 数据瞬时为 0
- 数据逐步增长
因此用户在更新过程中查询数据时,会明显感知数据变化,该方案虽然实现简单,但在大规模系统中风险较高。
4.3 新方案设想
综合上述方案,可以提出一种更加理想的设计思路:在数据更新过程中,新数据对用户不可见,待计算完成后再整体切换,见下图4-3所示。
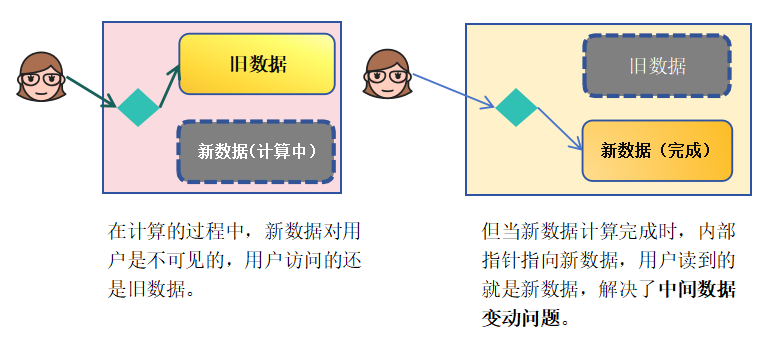
该思路类似于:双数据结构 + 指针切换机制,其基本逻辑如下:
- 系统内部维护两份数据
- 新数据在后台计算中时
- 查询仍访问旧数据
- 当新数据准备完成后,再统一切换到新数据
通过该方式,可以避免用户读取中间状态数据。
5. Doris 方案调研
基于上述设计思路,可以利用 Doris 提供的特性,实现无抖动数据更新机制。
核心思路为:利用临时分区构建新数据,并通过分区替换实现原子切换。
5.1 Doris数据库关键特性
什么是Doris,它是一款基于 MPP 架构的开源实时分析型数据库,主打极速查询、极简架构与实时数仓能力,简单理解就是:兼容 MySQL 协议的分布式分析型数据库。在本方案中,主要使用以下两个核心特性。
Unique Key 数据模型
Doris 提供多种数据模型,其中 Unique Key 模型 在本方案中具有重要作用,大概原来跟redis基本一样,见下图所示。
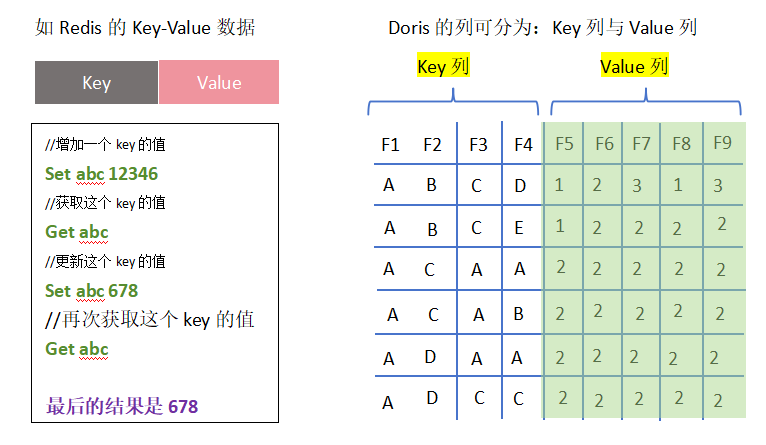
在 Unique Key 模型中:
- 部分字段定义为 Key 列
- 其余字段定义为 Value 列
- 当插入具有相同 Key 的记录时,新记录将覆盖旧记录
例如执行如下SQL:
Insert into table(f1,f2,f3,f4,f5,f6,f7,f8,f9)
values(A,B,C,D,1,1,1,1,1);
Insert into table(f1,f2,f3,f4,f5,f6,f7,f8,f9)
values(A,B,C,D,2,2,2,2,2);
Insert into table(f1,f2,f3,f4,f5,f6,f7,f8,f9)
values(A,B,C,D,3,3,3,3,3);
若:(f1,f2,f3,f4)被定义为 Unique Key,则最终数据库中仅保留:
A,B,C,D,3,3,3,3,3
该机制可有效支持:
- 覆盖更新
- 幂等写入
- 数据版本替换
在大规模数据更新场景中具有重要工程价值。
数据分区(Partition)机制
Doris 支持灵活的数据分区管理,详细技术使用可以到官网上查看,包括:
- 分区(Partition)
- 分桶(Bucket)
- 临时分区(Temporary Partition)
在本方案中,重点使用,逻辑分区与临时分区。
通过将数据按时间字段划分到不同分区,可以实现数据的高效管理与替换操作。
例如,可按日期字段创建分区:
PARTITION BY RANGE(report_date)
当数据写入时,将自动进入对应时间范围的分区。
此外,系统支持动态创建 临时分区,用于存储临时计算数据。临时分区具有如下特性:
- 可动态创建
- 不影响正式分区
- 可在计算完成后删除
- 支持分区级替换
该机制满足4.3节的新方案设想,为后续的数据无抖动更新提供了重要基础。
5.2 基于临时分区的数据防抖动方案
在前述设计思路的基础上,可以利用 Doris 的 Temporary Partition(临时分区)机制 实现数据更新过程中的隔离计算。
其核心思想为:在独立的临时分区中完成数据计算,在确认数据完整后,再通过分区替换机制一次性切换到正式分区。
该方案的基本流程如下:
在整个计算过程中:
- 用户查询使用的还是旧数据
- 新数据仅存在于临时分区
- 切换操作具有原子性
因此,用户无法感知数据更新过程中的中间状态。
5.2.1 基础实现流程示例
假设需要更新 2024-04-24 的广告消耗数据,其典型处理流程如下。
首先,从外部系统读取指定日期的数据:
facebook_data = fetch_url(
"http://facebook.com/api/2024-04-24"
)
随后,在目标表中创建临时分区:
ALTER TABLE adv_spend_table
ADD TEMPORARY PARTITION temp_partition_20240424
VALUES [('2024-04-24'), ('2024-04-25'));
需要注意:
该时间范围采用 左闭右开区间:
[2024-04-24, 2024-04-25)
然后,将读取到的数据写入临时分区:
INSERT INTO adv_spend_table
TEMPORARY PARTITION temp_partition_20240424
(report_date, adv_id, geo, spend, version)
VALUES (...);
待数据写入完成后,执行分区替换操作:
ALTER TABLE adv_spend_table
REPLACE PARTITION (p20240424)
WITH TEMPORARY PARTITION
(temp_partition_20240424);
该操作的本质为:使用临时分区中的数据整体替换原有正式分区的数据。
此操作具备以下特点:
- 原子性(Atomic Operation)
- 高度一致性
- 无中间状态暴露
因此,在数据更新过程中,用户始终只能读取到完整数据。
5.2.2 基础方案的实践意义
该方案能够有效解决以下问题:
- 数据更新过程中的余额波动问题
- 中间态数据被查询的问题
- 批量更新导致的数据不一致问题
在中等规模数据场景中,该方案已经能够满足大部分业务需求。然而,在超大规模数据场景(例如亿级数据写入)中,仍存在进一步优化空间。
6. 总结(Conclusion)
本文从实际业务问题出发,系统分析了数据更新过程中出现数据抖动的主要原因,并对多种实现方案进行了对比与优化。首先,通过分析传统数据库方案,指出以下常见问题,随后,提出基于 Doris 的数据更新优化思路,并重点介绍了以下核心技术。
- 分批更新导致中间态数据暴露
- 全量删除再插入造成瞬时数据缺失
- 异步数据处理带来的顺序不确定性
6.1 核心技术总结
本方案的关键技术包括:
Unique Key 数据模型
通过覆盖写入机制,实现幂等更新能力,减少重复数据问题。
Temporary Partition 临时分区
通过构建隔离计算环境,实现数据更新过程的可见性隔离。
Partition Replace 分区替换
通过原子切换机制,实现数据的整体替换,避免中间态暴露。
6.2 工程实践价值
在实际生产环境中,该方案能够显著提升系统稳定性,并有效解决以下问题:
- 数据查询结果波动问题
- 大规模数据更新风险
- 用户可见数据不一致问题
在亿级数据规模场景中,该方案表现出良好的稳定性与可扩展性。